En mi anterior trabajo lo instalé y configuré para monitorizar distintos entornos que gestionábamos y también para la monitorización remota de filesystems. He rescatado el pequeño documento que hice en su momento y este es el resultado después de completarlo con explicaciones más detalladas, ejemplos y alguna captura.
Lo primero que debo aclarar es que está basado en la versión 2.4 de Nagios, siendo la versión estable actual la 2.10. No debería haber muchas diferencias por lo que supongo que todo lo que voy a contar funcionará sin problemas. La máquina en la que monté el servidor Nagios es una Sun Fire 280R con Solaris 8 y obviamente no tenía permisos de root, por lo que la instalación está hecha con un usuario normal (vtprov) siendo su home /internet/vtprov. Además, al ser una máquina con Solaris no hay paquetes de binarios ya compilados, por lo que toca compilar desde el código fuente. El caso de la instalación para Linux debería ser similar.
Instalación
Después de descargar y desempaquetar el .tar generamos el fichero Makefile:
$ ./configure --prefix=PREFIX --with-nagios-user=SOMEUSER --with-nagios-group=SOMEGROUPDonde: PREFIX es la ruta en donde queremos instalar y que llamaremos $NAGIOS_HOME.
SOMEUSER es el usuario que ejecutará Nagios.
SOMEGROUP es el grupo del usuario que ejecutará Nagios.
Después simplemente compilamos:
$ make all
Y finalmente instalamos en la ruta que hayamos configurado anteriormente:
$ make install
Para comprobar el estado de los servicios, sistemas,... Nagios utiliza diversos plugins programados en C. Es necesario descargar y compilar dichos plugins e instalarlos en Nagios. La utilización de plugins hace que Nagios sea muy potente respecto a los sistemas que puede monitorizar puesto que si no existe ningún plugin que nos interese, siempre es posible crear uno a medida.
La compilación de los plugins es exáctamente igual a la de Nagios y una vez compilados deben almacenarse en el directorio $NAGIOS_HOME/libexec.
Configuración
Nagios se configura mediante archivos de texto que se encuentran en $NAGIOS_HOME/etc. Los principales archivos son:
A continuación muestro con un poco más de detalle los archivos de configuración y añado ejemplos de configuración. Sólo he seleccionado algunas partes concretas puesto que algunos son muy grandes y tienen muchas opciones. Cada una de ellas viene con una pequeña explicación sobre su utilización.
nagios.cfg
Hay que prestar especial atención a la opción check_external_commands puesto que sin habilitarla no podremos comprobar el estado de un servicio que deseemos en un momento determinado, sino que sólo se ejecutará la comprobación según se haya planificado.
# OBJECT CONFIGURATION FILE(S)
# Plugin commands (service and host check commands)
cfg_file=/internet/vtprov/nagios/etc/checkcommands.cfg
# Misc commands (notification and event handler commands, etc)
cfg_file=/internet/vtprov/nagios/etc/misccommands.cfg
# You can split other types of object definitions across several
# config files if you wish (as done here), or keep them all in a
# single config file.
cfg_file=/internet/vtprov/nagios/etc/bigger.cfg
# NAGIOS USER
nagios_user=vtprov
# NAGIOS GROUP
nagios_group=users
# EXTERNAL COMMAND OPTION
# This option allows you to specify whether or not Nagios should check
# for external commands (in the command file defined below). By default
# Nagios will *not* check for external commands, just to be on the
# cautious side. If you want to be able to use the CGI command interface
# you will have to enable this. Setting this value to 0 disables command
# checking (the default), other values enable it.
check_external_commands=1
[...]
checkcommands.cfg
Estos son algunos de los comandos (plugins) que podemos usar para comprobar el estado de los servicios. Por ejemplo, el comando check_http realiza una simple llamada GET a la máquina definida en el parámetro $ARG1$, al puerto $ARG2$ y a la URL $ARG3$. Esta llamada la usábamos para comprobar el estado de diversos servlets que estaban corriendo en distintas instancias de servidores tomcat.
El comando check_http_wm es una personalización del anterior (fijaos que el command_line es el mismo) pero se conecta con un usuario y password que pasamos como parámetro.
También muestro el ejemplo del ping y también el comando check_nrpe que veremos posteriormente para ejecutar scripts en máquinas remotas y en función del resultado lanzar o no una alarma.
define command{
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}
define command{
command_name check_http
command_line $USER1$/check_http -H $ARG1$ -p $ARG2$ --url=$ARG3$
}
define command{
command_name check_http_wm
command_line $USER1$/check_http -H $ARG1$ -p $ARG2$ -a USER:PASSWD
}
define command{
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -p $ARG1$ -c $ARG2$ -a $ARG3$ $ARG4$ $ARG5$
}misccommands.cfg
En mi caso cambié el command_line que venía por defecto por el que muestro a continuación puesto que así se envía más información en la alerta que nos llega por email.
# 'notify-by-email' command definition
define command{
command_name notify-by-email
command_line /usr/bin/printf "Subject: ** $NOTIFICATIONTYPE$ alert - $HOSTALIAS$/$SERVICEDESC$ is $SERVICESTATE$ ** %b\n\n ***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress: $HOSTADDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$SERVICEOUTPUT$" | /usr/bin/mail $CONTACTEMAIL$
}
bigger.cfg
Como ya he comentado este es el archivo de configuración en el que damos de alta todos los servicios que queremos monitorizar. Además, también definimos los periodos de monitorización, usuarios, agrupamos los servicios,...
# '24x7' timeperiod definition
define timeperiod{
timeperiod_name 24x7
alias 24 Hours A Day, 7 Days A Week
sunday 00:00-24:00
monday 00:00-24:00
tuesday 00:00-24:00
wednesday 00:00-24:00
thursday 00:00-24:00
friday 00:00-24:00
saturday 00:00-24:00
}
# 'workhours' timeperiod definition
define timeperiod {
timeperiod_name Workhours
alias "Normal" Working Hours
monday 08:00-19:00
tuesday 08:00-19:00
wednesday 08:00-19:00
thursday 08:00-19:00
friday 08:00-15:00
}
# 'vt-prov' contact definition
define contact {
contact_name vt-prov
alias Nagios Admin
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,u,r
service_notification_commands notify-by-email
host_notification_commands host-notify-by-email
email user1@empresa.com,user2@empresa.com
}
# 'host1' host definition
define host{
use generic-host
host_name host1
alias Servidor host1
address 172.24.88.169
check_command check-host-alive
max_check_attempts 10
check_period 24x7
notification_interval 120
notification_period 24x7
notification_options d,u,r
contact_groups vt-prov
}
# 'solaris-servers' host group definition
define hostgroup{
hostgroup_name solaris-servers
alias Solaris Servers
members host1,host2,host4,host6
}
Ping
define service{
use generic-service
host_name host1
service_description PING
is_volatile 0
check_period 24x7
max_check_attempts 4
normal_check_interval 1
retry_check_interval 1
contact_groups vt-prov
notification_interval 120
notification_period 24x7
notification_options w,u,c,r
check_command check_ping!100.0,20%!500.0,60%
}Servlet en Tomcat
define service{
use generic-service
host_name host2
service_description ENTORNO1 - Servicio2
is_volatile 0
check_period 24x7
max_check_attempts 1
normal_check_interval 5
retry_check_interval 1
contact_groups vt-prov
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
check_command check_http!host2!10102!/servicio/jsp/autent/login.jsp
}Ocupación Filesystem
define service{
use generic-service
host_name host2
service_description host2 - /var
is_volatile 0
check_period 24x7
max_check_attempts 1
normal_check_interval 5
retry_check_interval 1
contact_groups vt-prov
notification_interval 120
notification_period 24x7
notification_options w,u,c,r
check_command check_nrpe!7997!check_disk!7!5!/var
}define servicegroup{
servicegroup_name ENTORNO1 - TOMCATs
alias ENTORNO1 - TOMCATs
members host2,ENTORNO1 - Servicio2,host2,ENTORNO1 - Servicio3,host2,ENTORNO1 - Servicio8
}Una vez definidos los servicios que deseamos monitorizar, podemos verificar si el archivo de configuración es correcto o contiene algún error. Desde el directorio $NAGIOS_HOME/bin:
$ nagios -v ../etc/nagios.cfg
Nagios 2.4
Copyright (c) 1999-2006 Ethan Galstad (http://www.nagios.org)
Last Modified: 05-31-2006
License: GPL
Reading configuration data...
Running pre-flight check on configuration data...
Checking services...
Checked 82 services.
Checking hosts...
Checked 5 hosts.
Checking host groups...
Checked 1 host groups.
Checking service groups...
Checked 16 service groups.
Checking contacts...
Checked 1 contacts.
Checking contact groups...
Checked 1 contact groups.
Checking service escalations...
Checked 0 service escalations.
Checking service dependencies...
Checked 0 service dependencies.
Checking host escalations...
Checked 0 host escalations.
Checking host dependencies...
Checked 0 host dependencies.
Checking commands...
Checked 26 commands.
Checking time periods...
Checked 4 time periods.
Checking extended host info definitions...
Checked 0 extended host info definitions.
Checking extended service info definitions...
Checked 0 extended service info definitions.
Checking for circular paths between hosts...
Checking for circular host and service dependencies...
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
Como no hay ningún error podemos arrancar Nagios:
$ nagios -d ../etc/nagios.cfg
En este momento se empezarían a monitorizar los sistemas que tengamos definidos y se enviarían notificaciones por email si se han configurado.
Interfaz Web
Para poder interactuar con el sistema y ver todo de un modo gráfico es necesario configurar la consola web de Nagios. Para ello es necesario un servidor Apache. Instalamos el servidor y en el archivo httpd.conf añadimos lo siguiente:
ScriptAlias /nagios/cgi-bin "/internet/vtprov/nagios/sbin/"
<Directory "/internet/vtprov/nagios/sbin">
AllowOverride AuthConfig
Options +ExecCGI
Order allow,deny
Allow from all
</Directory>
Alias /nagios "/internet/vtprov/nagios/share"
<Directory "/internet/vtprov/nagios/share">
Options None
AllowOverride AuthConfig
Order allow,deny
Allow from all
</Directory>
Reiniciamos apache y ya nos deberíamos poder conectar a la consola de administración:
 |
Control de Acceso
Se pueden definir distintos usuarios para conectarse a Nagios con diferentes permisos y que verán únicamente los servicios en los que se hayan añadido como contacto. Para ello utilizamos las opciones de autenticación que ofrece Apache.
Creamos el archivo .htaccess en los directorios share y sbin con el siguiente contenido:
AuthName "Acceso a Nagios"
AuthType Basic
AuthUserFile /internet/vtprov/nagios/etc/htpasswd.users
require valid-user
Y creamos el archivo de passwords desde el directorio bin de la instalación de Apache añadiendo el usuario nagios.
$ htpasswd -c /internet/vtprov/nagios/etc/htpasswd.users nagios
Ahora al conectarnos a Nagios nos aparecerá la típica ventana solicitando nuestro usuario y password.
 |
Comandos remotos
Para poder ejecutar scritps en máquinas remotas, como por ejemplo, para comprobar el tamaño de los filesystems de otras máquinas, necesitamos instalar un pequeño servidor en dichas máquinas. Este servidor se llama NRPE (Nagios Remote Plugin Executor). Es necesario descargarlo y compilarlo tal y como hemos hecho con Nagios.
La configuración es muy sencilla: En cada máquina que queramos monitorizar la ocupación de sus filesystems debemos configurar el archivo nrpe.cfg en el que básicamente hay que indicar el puerto en el que queremos levantar el servidor, el usuario y el grupo que lo ejecutan y activar la opción para permitir recibir comandos remotos con parámetros. El fichero de configuración tiene el siguiente aspecto (como antes, incluyo sólo lo más importante).
# PORT NUMBER
server_port=7997
# SERVER ADDRESS
server_address=172.24.88.169
# ALLOWED HOST ADDRESSES
# This is a comma-delimited list of IP address of hosts that are allowed
# to talk to the NRPE daemon.
allowed_hosts=127.0.0.1,172.24.86.11
# NRPE USER
nrpe_user=nrpe
# NRPE GROUP
nrpe_group=users
# COMMAND ARGUMENT PROCESSING
# This option determines whether or not the NRPE daemon will allow clients
# to specify arguments to commands that are executed. This option only works
# if the daemon was configured with the --enable-command-args configure script
# option.
#
# *** ENABLING THIS OPTION IS A SECURITY RISK! ***
# Read the SECURITY file for information on some of the security implications
# of enabling this variable.
#
# Values: 0=do not allow arguments, 1=allow command arguments
dont_blame_nrpe=1
# COMMAND DEFINITIONS
command[check_disk]=/home/user/nrpe/check_disk.sh $ARG1$ $ARG2$ $ARG3$
Hay que destacar la opción dont_blame_nrpe ya que tal y como se indica activarla puede representar un problema de seguridad porque estamos aceptando parámetros y podría realizarse algún tipo de ataque a la máquina por este medio. En mi caso lo habilité porque el script que comprueba el tamaño del filesystem necesita dichos parámetros y no representaba ningún problema de seguridad.
Al final también hemos añadido el comando remoto que se ejecutará (check_disk) y la llamada al script con los parámetros necesarios. Este script debe existir en la máquina de la que deseamos monitorizar los filesystems.
Recordemos que antes definimos la ejecución del script check_disk (para un filesystem y máquina concretos) como:
check_nrpe!7997!check_disk!7!5!/varEn esta llamada 7997 es el puerto del nrpe en la máquina remota, check_disk es el nombre lógico del script y 7, 5 y /var son los parámetros del script. Éste comprueba el porcentaje de espacio libre del filesystem que recibe como parámetro y lo compara con los dos umbrales que le pasamos. Si es menor de un 7% genera un warning y si es menor de un 5% genera un error crítico.
El script check_disk.sh que acabamos de ver y que definíamos anteriormente en el archivo bigger.cfg es el siguiente:
#!/bin/ksh
# check_disk.sh: Comprueba el tamaño de un filesystem y
# devuelve el estado en función de dos umbrales definidos.
#
# Iván López Martín
warning=$1
critical=$2
filesystem=$3
STATE_OK=0
STATE_WARNING=1
STATE_CRITICAL=2
size=`df -k $filesystem | grep $filesystem | awk '{print $4}'`
sizeMB=`echo "$size/1024" | bc`
percentage=`df -k $filesystem | grep $filesystem | awk '{print $5}' | sed -e s/%//g`
freePercentage=`echo "100-$percentage" | bc`
if [ "$freePercentage" -le "$critical" ]; then
echo "DISK CRITICAL - free space: "$filesystem" $sizeMB MB"
return $STATE_CRITICAL
fi
if [ "$freePercentage" -le "$warning" ]; then
echo "DISK WARNING - free space: "$filesystem" $sizeMB MB"
return $STATE_WARNING
fi
echo "DISK OK - free space: "$filesystem" $sizeMB MB"
return $STATE_OK
Con los scripts remotos configurados arrancamos el demonio nrpe:
$ nrpe -c nrpe.cfg -d
Como veis, me he hecho mi propio script para comprobar remotamente los filesystems de las distintas máquinas. Aunque dije inicialmente que los plugins que vienen con Nagios están escritos en C, se puede utilizar cualquier lenguaje que soporte la máquina para comprobar el estado del servicio que deseemos.
Este script nos era especialmente útil sobre todo para comprobar la ocupación del filesystem /var. Cuando veíamos que estaba bastante lleno sólo teníamos que enviar un email a administración Unix para que borrasen logs antiguos y nos liberaran algo de espacio.
Interfaz gráfica
A continuación muestro una serie de capturas de pantalla de la interfaz gráfica con todos los servicios que teníamos configurados en su momento.
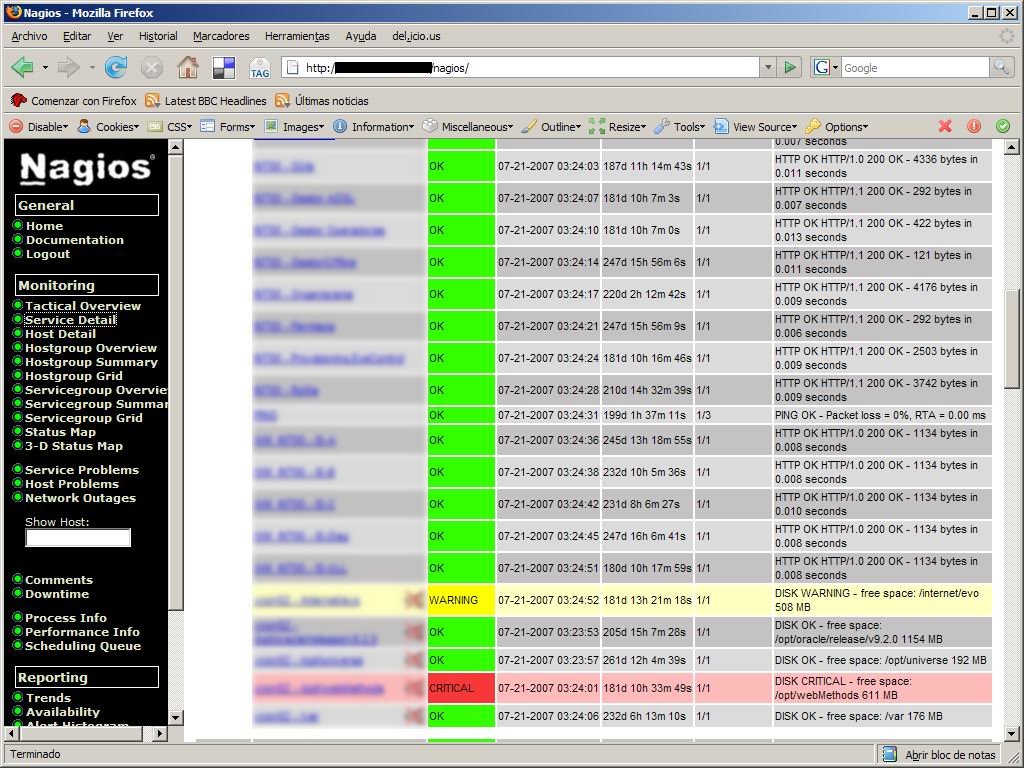 |  |
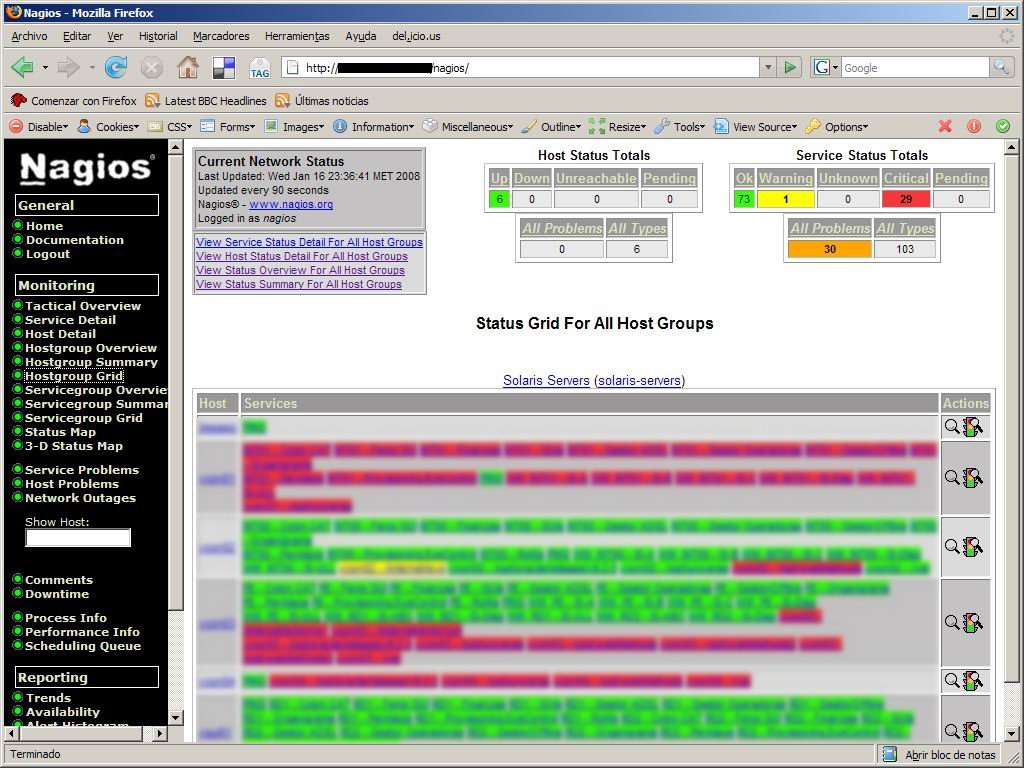 |  |
Conclusiones
Lo que más me gusta de Nagios es que es muy sencillo de configurar y que con el simple hecho de dar de alta un servicio, automáticamente ya lo estamos monitorizando.
En su momento también probé herramientas como Hyperic HQ y aunque visualmente son más bonitas, descubren automáticamente los servicios que hay corriendo en las máquinas,... al final son más engorrosas. En mi caso, en algunas máquinas descubría "demasiados" servicios y había que estar eliminando todos los que no queríamos monitorizar. Además, había que definir una a una las alarmas para cada uno de esos servicios. Al final, después de probarla durante un tiempo la descarté y me quedé con Nagios.
72 comentarios:
Muchas gracias por el artículo. Hace tiempo que vengo siguiendo el Nagios y, aunque no lo he llegado a probar, me parece que las últimas versiones tienen un aspecto realmente magnífico. Aunque aún le queda camino por andar, creo que va a plantarle cara a muchas soluciones cerradas comunes en el sector...
Yo he desplegado Nagios hace un par de semanas y me gustaría saber como obtienes tu el espacio en disco, la CPU utilizada, memoria, etc en equipos remotos. Si el nagios corre en la máquina en cuestión hay modulos para ello, pero ¿En remoto?. Ideas son bienvenidas.
¡Hola a los dos!
[Super coco]: Gracias a ti por el comentario. Como dices las nuevas versiones parece que están mucho más logradas y son mucho mejores que la anterior. A mi me encanta Nagios por su potencia y flexibilidad que otras soluciones no tienen.
[Gura]: Para obtener información de las máquinas remotas necesitas instalar en ellas el NRPE que comento en el artículo. Luego el servidor Nagios se encarga de comunicarse con el demonio nrpe de las máquinas remotas y ejecutar el script que te interese.
La obtención del tamaño de los filesystems remotos la hacía como comento y con el script que he puesto. Para obtener el resto de información puedes utilizar uno de los scripts que proporciona Nagios o hacerte uno a medida.
Espero habértelo aclarado un poco, sino, no dudes en preguntar de nuevo.
Saludos, Iván.
me-he-colao. Lo voy a montar esta semana.
[Gura]: Ya nos contarás qué tal te ha ido y si tienes alguna duda.
Saludos, Iván.
Pues hay un montón de gente que piensa que configurar Nagios es difícil ¿te lo puedes creer? A mi es una herramienta que me resulta imprescindible!
Para quien quiera alguna cosilla más (como la forma de dibujar mapas gráficos), yo hice también un tutorial hace ya un añito en una serie de cuatro posts:
http://blog.unlugarenelmundo.es/?s=nagios
Salud!
Hola Jose María,
a mi también me parece muy sencillo y potente.
Yo en su momento me estuve pegando para intentar dibujar los gráficos pero al final no lo conseguí y por falta de tiempo no investigué más.
Gracias por el comentario y por el enlace.
Saludos, Iván.
Buenas.
Como alternativa a Nagios yo uso Cacti, que quizas no es tan potente pero con una Ubuntu se pone en marcha en 20 minutos.
Lo digo como una alternativa, no como un mejor sistema, ya que creo que van a al par.
Como ya te dije, da gusto leerte. Por cierto te han meneado el apunte. Felicidades.
Hola Taber,
también he utilizado Cacti pero ha sido para ver estadísticas de la máquina sobre el consumo de memoria, cpu,... En una ocasión nos sirvió para detectar que una máquina tenía el iowait muy alto y analizamos más a fondo lo que pasaba. Yo lo veo como complemento a Nagios para analizar la máquina desde más alto nivel.
Gracias por el comentario y por los halagos ;-)
Saludos, Iván.
Hola Iván, antes de nada felicitarte por el detallado tutorial.
Te quería pedir una cosilla.
Por lo que he entendido (corrígeme si me equivoco) tan sólo instalando el servidor Nagios en una máquina estamos listos.
Hace poco puse Zabbix, y este necesita un agente en cada máquina que quieres monitorizar y este agenta manda información de esa máquina al servidor, excepto para routers y otros dispositivos que puede manejar por SNMP.
Esto no me gusta mucho, ya que hay algunas máquinas que están bastante cargadas como para meterle encima el zabbix_agent corriendo todo el tiempo.
Perdón por el tocho, saludos y gracias.
Hola *,
yo he usado zabbix y nagios en entornos con unos cuantos equipos y servicios y en respuesta a bytecoders diré que los dos necesitan agentes instalados para hacer los checks.
Claro que si lo unico que quieres es comprobar pings no te hace falta desplegar agentes con zabbix ni con nagios. Pero para mirar %cpu y %disco ... etc, si.
A mi, la verdad es que me gusta mas zabbix, es mas amigable la interfaz y en cualquier momento te puedes montar una grafica de la variable monitorizada y tendencias.
La diferencia principal que encuentro entre nagios y zabbix es que nagios comprueba estados de servicios, y almacena información sobre si la variable esta en valores de OK, critico, o warning; mientras que zabbix almacena el valor de las variables, y tu le defines las alertas; con esto quiero decir que con nagios en principio solo sabras si la cpu esta ok si esta por debajo del 70%, y en zabbix se almacena el 70% y le defines las alertas a posteriori. no se si me he explicado.... en fin.
en cualquier caso, yo ahora estoy usando los dos, nagios para la infraestructura y zabbix para hacer pruebas de stress en equipos concretos. lo malo de nagios, es que para cambiarle cosas de configuracion hay que bajar a tocar los .cfg's, o ponerte el monitor architect ...
las ultimas versiones de zabbix ya trabajan con el concepto "aplicacion" que es la agrupacion de servicios de la misma o distintas maquinas, p ej una base de datos en un equipo + 4 apaches en 4 equipos + servicio nfs de otra + servidor de correo = aplicacion A, con lo que se logra un control bastante bueno.
en fin, las dos soluciones son buenas si hacen lo que uno quiere.
Saludos!
Hola,
creo que con la excelente explicación de ChemiCephalus ha quedado muy claro.
Primero aclaro que no he trabajado con zabbix, pero en nagios el "agente" NRPE no envía nada por sí mismo, sino que es el servidor el que le pide la información. Yo he tenido el nrpe corriendo en máquinas bastante cargadas y no muy potentes y no se notaba nada. Eso sí, sólo lo utilizaba para monitorizar tamaños de filesystems. La utilización de cpu y memoria lo miraba a través de gráficas de Cacti.
Saludos y gracias por vuestros comentarios, Iván.
No se si conoceis Oreon.
Es una interfaz para Nagios, que hace que la tediosa tarea de configurar los ficheros a través de texto plano, sea muy simple, a través de una interface web.
Además, se hace tan ameno, que puedes utilizarlo sin ni siquiera tener idea de cómo funciona Nagios. Este fué mi caso. Empezé como becario en una empresa y me pusieron a administrar el Oreon: ni decir tiene que yo no había escuchado hablar en mi vida de Oreon o de Nagios, y no me fué en absoluto dificil.
Además, para los nostálgicos, siempre puedes tocar a nivel de asrchivos de configuración.
Un saludo a todos
Hola Anónimo,
yo no conocía Oreon pero según comentas parece muy interesante para empezar a configurar Nagios e ir aprendiendo poco a poco. Así podemos analizar los archivos de configuración y ver las distintas posibilidades que ofrece.
Me lo apunto porque puede ser muy útil!.
Muchas gracias y saludos, Iván.
Estaba haciendo un post en el foro que administro y aún lo tenía sin terminar. Tu artículo me parece genial y me ayudará seguro.
A parte estoy muy familiarizado con Nagios, ya que en el trabajo lo tenemos en todos los equipos.
Voy a probar las recomendaciones que se han hecho por los comentarios.
Gracias de nuevo
Hola Figue,
me alegro de que te haya gustado y resultado útil el artículo.
Muchas gracias!.
Saludos, Iván.
Para monitorizar dispositivos de red, que tengan agente snmp, tambien está muy bien el cacti
Hola Alejandro,
ya conocía Catci y de hecho en mi anterior trabajo también lo usábamos. Lo que pasa es que no lo instalé yo.
Saludos, Iván.
Tengo el siguiente Script que corre en el server asterisk:
warning=$1
critical=$2
calling=$3
STATE_OK=0
STATE_WARNING=1
STATE_CRITICAL=2
call_activas=$(/usr/sbin/asterisk -rx "core show channels" | grep "active calls" | awk '{ print $1}')
echo "$call_activas"
call_registry=$(/usr/sbin/asterisk -rx "sip show peers" | grep "OK" | awk '{print $1}' | wc -l)
echo "$call_registry"
canales_free=`echo " $call_registry - $call_activas " | bc`
echo "$canales_free"
if [ $canales_free -le $critical ]; then
echo "CHANELS CRITICAL" $call_activas "$canales_free"
exit $STATE_CRITICAL
fi
if [ $canales_free -le $warning ]; then
echo "CHANELS WARNING"
exit $STATE_WARNING
fi
echo "CHANELS OK"
exit $STATE_OK
=================
en el nrpe.cfg del server de asterisk:
command[check_canales]=/home/usuario/script/canales $ARG1$ $ARG2$ $ARG3$
=============================
en el server de monitoreo nagios (commands.cfg):
define command{
#command_name check_chanels
command_name check_canales
command_line /usr/lib/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -p 5666 -C /home/usuario/script/check_canales -p $ARG1$ -a ARG2$ $ARG3$
#command_line /usr/lib/nagios/plugins/check_nrpe -H $HOSTADDRESS$ -C /home/usuario/script/$ARG2$
}
y la consulta desde el services.cfg la realizo asi:
check_command check_nrpe!check_canales!7!5
los permisos estan ok y usuario + grupo.
Me falto el problema del script:
los parentesis cuadrados no me funcionaron, y en el nagios me daba este error:
(No output returned from plugin)
una manito. Gracias
Hola Anónimo,
he estado revisando el código que me has pasado y he encontrado un par de errores:
- El principal y por el que creo que obtienes el error de No output returned from plugin es porque en el script estás usando exit $STATE_CRITICAL en lugar de return $STATE_CRITICAL. Cambia todos los exit por return.
- En el commands.cfg te falta un $ en esta línea: /home/usuario/script/check_canales -p $ARG1$ -a ARG2$ $ARG3$. En ARG2 sólo tienes puesto un $ por detrás y te falta el de delante.
- Respecto a los argumentos, según veo en tu script sólo estás usando el parámetro $1, por lo que en la configuración y en la llamada:
check_command check_nrpe!check_canales!7!5 sólo deberías poner ese único parámetro que utilizas luego en tu script. Creo que el problema que has tenido ha sido al copiar mi script y no eliminar las partes que no te hacían falta.
Espero que con todo esto logres solucionar tu problema. Si es así, por favor pon otro comentario para contárnoslo.
Saludos, Iván.
buenas, estos son los warning que obtengo cambiando parametros.
sh canales
15
268
253
canales: line 27: [: : integer expression expected
canales: line 31: [: : integer expression expected
CHANELS OK
canales: line 37: return: can only `return' from a function or sourced script
Hola Anónimo,
lo primero que tienes que hacer es que tu script funcione correctamente desde la línea de comando en la ejecución de nagios.
También te sugiero no hacer tantos echo's porque ten en cuenta que luego eso es lo que se muestra en la web de administración de nagios. Sólo deberías hacer uno cada vez, justo antes del return (tal y como tengo hecho en mi script).
Y por último, definir el script, con la primero línea como #!/bin/ksh (o lo que corresponda).
Saludos, Iván.
bueno podria hacer tarde ya para el script pero yo hice esta modificacion y la parecer si jala solo falta hacer las ultimas pruebas
se los dejo
#!/bin/bash
warning=$1
critical=$2
#calling=$3
STATE_OK=0
STATE_WARNING=1
STATE_CRITICAL=2
active_calls=$(/usr/sbin/asterisk -rx "show channels" | grep "active calls" | awk '{ print $1}')
echo "Total de lineas activas $active_calls"
call_registry=$(/usr/sbin/asterisk -rx "sip show peers" | awk '{print $1}' | wc -l)
echo "Total de registros $call_registry"
free_channels=`echo " $call_registry - $active_calls " | bc`
echo "canales libres $free_channels"
if [ $active_calls -ge $critical ]; then
echo "CHANELS CRITICAL" $active_calls #"$free_channels"
exit $STATE_CRITICAL
fi
if [ $active_calls -ge $warning ]; then
echo "CHANELS WARNING"
exit $STATE_WARNING
fi
echo "CHANELS OK"
exit $STATE_OK
Hola Kurama,
me alegro de que finalmente hayas podido solucionar el problema con el script y de que te funcione correctamente.
Saludos, Iván.
Hola Ivan
Muy bueno el articulo. Yo utilizo nagios hace aprox un mes. Y me va muy bien. Lo utilizo para monitorizar servidores Windos con NSCLIENT++ (que es un cliente como NRPE pero para windows) y va bastante bien. Provee aplicaciones gráficas para configurarlo pero estas están muy lejos de las nuevas versiones de Nagios . Estuve utilizando Oreon pero habia funciones o mejoras que el nagios 2 no tenia asi que me pasee. Para algunos que me da la impresion de que son reacios a instalar agentes en los servidores pueden evitar esto haciendo consultas a traves de SNMP. Tiene que tenerlo instalado. En los dispositivos de red (routers, switcher , impresoras ,etc) ya vienen solo hay que habilitarlos para poder hacer la consulta. Y en los servidores windows debeis instalarlo desde "agregar y quitar programas - componentes de windows -en Herramientas de Administracion y monitorizacion - agregar simple Network Managment Protocol (SNMP)"
En fin espero les sirva de ayuda.
Saludos
Olrait
Hola Olrait,
muchas gracias por contarnos tu experiencia y por NSClient++. Me lo apunto por si alguna vez tengo que monitorizar una máquina windows.
Miraré también Oreon porque tiene muy buena pinta.
Gracias por el comentario.
Saludos, Iván.
Buenas Iván:
me ha gustado mucho el articulo tengo nagios montado con ubutu y tengo la duda de como monitorizar elemntos de red cisoc y 3com con snmp, alguien me podria dar una ayudita.
gracias
Hola Anónimo,
lo siento pero no he utilizado la monitorización con snmp, no te puedo ayudar. Busca un poco en google que seguro que no es muy complicado de encontrar y alguien ya lo ha hecho.
Saludos, Iván.
Buenas tardes,
Estoy empezando con nagios, es decir, no tengo gran idea, se monitorizar equipos, switches, router, vamos lo básico. Mi idea es monitorizar puertos especificos, como se podria hacer?¿
Basicamente quiero saber si una ip publica tiene un puerto determinado abierto:
Ejemplo: la ip xxx.xxx.xxx.xxx si tiene el puerto 4662
Muchas gracias de ante mano.
Hola [^ChIkO_Dc^],
claro que se puede saber si un puerto responde o no. Si te fijas, en el tutorial muestro el comando check_http:
define command{
command_name check_http
command_line $USER1$/check_http -H $ARG1$ -p $ARG2$ --url=$ARG3$
}
que, aunque tiene ese nombre, en los parámetros ves que recibe un host (arg1), un puerto (arg2) y una url (arg3). El último parámetro lo podrías quitar y entonces sólo le tendrías que pasar la ip y el puerto.
Saludos, Iván.
P.D: Sé bueno que ese es el puerto del emule... ;-)
Hola
Tengo un requerimiento, nuestra compañía conoce y valora muy bien Nagios, pero necesita tener el producto sobre windows....¿ alguien tiene algun antecedente ?
Hola Anónimo,
lo siento pero yo no te puedo ayudar. Siempre he trabajado con nagios en máquinas unix.
Si lo que te refieres es a instalar algún cliente para monitorizar máquinas windows, creo que sí es posible, pero nunca los he utilizado.
Espero que tengas suerte con la búsqueda.
Saludos, Iván.
Hola q tal?
1 pregungta hay alguna fomra de hacer q nagios detecte todos los pcs automaticamnte y no ir creandno archivos por cada uno de estos?
Saludos y muchas gracias
SI me puedes ayudarr o alguna paguina
MI mail , tabare_81@hotmail.com
Hola Anónimo,
lo siento pero no conozco ninguna opción de Nagios que permita ratrear automáticamente todos los Pcs de la red. Tal vez alguna de las últimas versiones incluya alguna opción para esto. Echa un vistazo a su web.
Saludos, Iván.
Hola.
Existe un script en perl (nmap2nagios), para hacer un autodescovery, que genera .cfg a partir del nmap.
http://nagioswiki.com/wiki/index.php/Autocreating_Nagios_Configuration_with_Nmap_and_Nmap2Nagios.pl
saludos. Carlos
una consulta
alguien ha utilizado nagios con instancias mediante el addon NDOUTILS ?
[Carlos]: Muchas gracias por la información. No conocía ese script. La verdad es que tiene muy buena pinta y puede ser muy útil.
[Cali]: Lo siento pero con el NDOUTILS no he trabajado. No te puedo ayudar.
Saludos, Iván.
Hola Ivan, buenisimo el "tuto" sobre Nagios. Lo instale en Fedora Core 7, y todo funcionó correctamente hasta que llegué a la interfaz web, la cual me tira un error de Internal Server Error. He estado googleando y sé que es por los cgi. He cambiado permisos, directivas de Apache, y muchas pruebas más. No sé si a alguien le ha ocurrido lo mismo.
SalU2
Pablo,
Mira si esto te sirve http://www.nagios.org/faqs/viewfaq.php?faq_id=55
Gracias Cali, le echaré un vistazo. El error que me lanza es el 403 de Apache. Investigaré ese link a ver que tal. Ya ire contando.
SalU2
Hola Ivan, estuve leyendo tu tutorial y me surge un problema a la hora de trabajar con grandes volumenes de servidores.
Acerca de la configuración del statusmap en nagios. El problema o la duda es que no se como hacer para q no salgan todas las máquinas apelmazadas o solapadas en el status map de forma q no se distinga practicamente una de otra.
Gracias por la ayuda y felicitaciones :)
Hola Francisco,
lo siento pero no te puedo ayudar. Ya no tengo acceso a ese Nagios puesto que era de un trabajo anterior. No obstante, no recuerdo que saliera todo solapado.
Me alegro de que te haya gustado el tutorial, gracias!.
Saludos, Iván.
Hola Iván, soy Alvaro, antiguo compañero en Cap, te acuerdas?. Bueno dado que veo que estas hecho un experto en esto, mi pregunta es la siguiente: Es posible con Nagios monitorizar el resultado de la ejecucion de un .bat personalizado y mandar alertas en funcion del mismo??. Un saludo tío y gracias de antemano
Hola Álvaro,
claro que me acuerdo!. Te voy a matar!!. Me tienes en el facebook y también mi correo en el blog y vas dejando por aquí información sensible de donde he trabajado y demás... :-P.
Respecto a tu pregunta, en el post tienes el script de ejemplo que hice para monitorizar los filesystems de las máquinas. El script se llama check_disk.sh y como ves, defino los valores OK, WARNING y CRITICAL y en función de las comprobaciones que hago devuelvo uno de los 3. Eso nagios lo interpreta y pones las alarmas correspondientes.
Espero que te sirva.
Un abrazo tío!
Ya que estamos, promocionemos el producto de una empresa española que genera software libre.
La empresa es Artica S.T., y su producto: pandora.
Lo que están haciendo los chicos de Artica tiene mucho valor. Y apoyando (y creando) el software libre desde sus inicios en este país de pandereta.
Hola Villacampa,
muy interesante!, muchas gracias por el enlace. Lo he revisado un poco y tiene muy buena pinta!.
Saludos, Iván.
Buenas,
Lo primero enhorabuena por el articulo. Yo estoy montando nagios para alimentar otra herramienta que tiene mi empresa.
Esta herramienta ya tiene de muchiiisimos scripts que retornan un 0,1 o 2 segùn el resultado del check y quisiera rehusarlos para nagios pero ... sin nrpe ;).
He mirado que se puede hacer con check_by-ssh pero extrañamente aunque tengo intercambiadas las claves cuando hago el check-ssh me pide passwd y si hago un ssh desde consola no...
¿Alguien ha conseguido algo con chec_by_ssh?
Gracias!
Hola Ivan, estoy trabajando con Cacti pero tengo un problema y no entiendo; dentra de mi red algunas maquinas logro graficarlas y otras obtengo error snmp.
De antemano gracias.
mi prefix=/usr/local/nagios
Cuando dices:
La compilación de los plugins es exáctamente igual a la de Nagios y una vez compilados deben almacenarse en el directorio $NAGIOS_HOME/libexec.
se refiere que debo hacer:
./configure prefix=/usr/local/nagios/libexec --with-nagios-user=nagios --with-nagios-group=nagios
y luego haría make o gmake all, y make o gmake install y ya lo instalaría en la ruta especificada en --prefix?
(esto estaría bien?)
No tengo mucho conocimiento de esto..estoy aprendiendo. ^^
gracias por compartir lo que sabes ;)
por cierto: lo estoy intentando instalar en opensolaris...es igual no?
Hola,
[angel]: Gracias, me alegro de que te haya gustado. Siento no poder ayudarte porque en mi caso con el nrpe me bastaba y no tuve que utilizar ssh.
[Manolo]: Aunque conozco Cacti, no he lo he configurado ni administrado. Lamento no poder ayudarte.
[Anonimo]: Aunque hace ya mucho tiempo que lo hice, creo que es lo que dices. Pones el mismo comando de compilación y los binarios los almacenas en libexec. Sí, como estás compilando debería funcionar en cualquier sistema: openSolaris, HP-UX, Linux,...
Saludos y gracias por vuestros comentarios, Iván.
saludos....
consulta, para monitorear discos en solaris, cual seria la pauta, ya que al correr los servicios me arroja este error:
could not open pipe: /usr/bin/ssh -l nagios "ip_maquina_remota" '/usr/lib/nagios/plugins/check_disk -w '90' -c '95' -p '/'
Hola Kamehb,
como comento al principio del artículo, el tutorial está basado en solaris, pero en mi caso no utilicé ssh. Creo que algún parámetro no lo estás pasando correctamente, pero sin la máquina y la instalación de Nagios a mano me temo que no puedo ayudarte.
Saludos, Iván.
Hola estimados,
les cuento estoy trabajando con nagios en mi empresa y tengo lo siguiente.
la mayoria de los equipos se monitorea asi;
desde el servidor de nagios a un servidor en el cliente(RMA), y luego desde este equipo con check_nrpe monitoreo otros servidores del cliente. hasta ahora todo bien pues los servidores (RMA) son linux en su mayoria. estos dias instalaron en un cliente un servidor RMA con windows. instale NSClient++ y NRPE_NT, que son para windows. Los chequeos locales del RMA sin problemas. Pero no tengo el pligin para saltar del RMA a los otros equipos de este nuevo cliente. la verdad estoy complicado llevo varios días buscando y nada.... alguien que me ayude por favooor....
saludos, Erick
Hola El Litro,
lo siento pero yo no te puedo ayudar, sólo he monitorizado máquinas unix con Nagios, nada de windows.
Saludos, Iván.
Buenas Ivan,
necesito ayuda con Nagios, quiero monitorizar las canales SIP, IAX y DAHDI de mi Asterisk y tambien me gustaria que me controlase el estado del proveedor Gizmo 5. He estado leyendo sobre eso pero lo máximo que he conseguido es añadir los servicios de los canales pero no pasan de estado CRITICAL.
Hola Davidin,
lo siento pero no he monitorizado (ni siquiera he utilizado) Asterisk, así que me temo que no te puedo ayudar.
Saludos, Iván.
Buenas noches Ivan
Gracias por la informacion.
La pregunta es la siguiente:
1. Necesito crear una alarma para controlar el trafico de red entre dos routers. La alarma de Nagios puede chequear el estado de los mismos, pero se necesita que muestre una alerta cuando no haya trafico o cuando el trafico supere o este por debajo de ciertos parametros. Te ha tocado esa situacion?
2. Has escuchado hablar de WMI. Es un protocolo que funciona al igual que el SNMP pero es propio de Windows, Ahora, lo que necesito es saber como enlazar Linux con Windows y utilizar un script que le pase valores a Nagios a traves de esa consulta. Ya tengo el script, pero atora en la libreria COM que utiliza el protocolo en Windows y que no deja al php de linux ingresar.
Gracias de antemano y saludos cordiales.
Hola Anónimo,
lamento no poder ayudarte pero en su momento lo único que monitorizaba eran servicios y ocupación de filesystems con el script que indico. Además todas las máquinas eran unix, ninguna windows.
Saludos, Iván.
@Anónimo:
La cuestión sería obtener ese valor por SNMP. No sé si con Nagios se puede, pero con un broser SNMP podrías mirar si tu router ofrece algun contador que se parezca a lo que pides...
quimicefa, con Nagios pueden monitorear cualquier dispositivo que tenga SNMP. En Google hay bastante explicando, inclusive yo monitoreo algunas UPSs. Saludos.
HOLA, UN SALUDO A TODOS LOS LECTORES.
YO TENGO UNA DUDA: NECESITO MONITOREAR UNOS DISPOSITIVOS QUE ESTAN ALMACENADOS EN UNA PAGINA WEB, YA LOGRE QUE MONITOREE LA DIRECCION DE LA PAGINA PRIENCIPAL, AHORA LO QUE QUIERO ES VER EL ESTADO DE TODOS LOS DISPOCITIVOS ALMACENADOS EN ESTA ¿ALGUNO DE USTEDES PUEDE AUXILIARME?
DE ANTEMANO GRACIAS.
Hola Ma. Beatriz,
no entiendo muy bien tu duda, quieres monitorizar los dispositivos de una web, ¿eso qué es?.
Saludos, Iván.
Hola,
soy principiante en Nagios, Cacti y Centreon, que son los primeros que he instalado.
Pero estoy perdidisimo en añadir plugins, mayormente en lo que estoy interesado no es en monitorizar discos duros y demas componentes, sino estoy interesado en monitorizar servicios como Apache2 , MySQL, etc.
Me podriais informar un poquito sobre el tema?
Muchas gracias y un saludo.
Pd. Estupendo el post
Léete el tutorial de Nagios, está todo perfectamente explicado (http://nagios.sourceforge.net/docs/nagioscore/3/en/pluginapi.html). Saludos a la gente que usa Nagios, herramienta noble si las hay...
Hace poco que utilizo Nagios y aún me falta comprender algunos aspectos...
Necesito monitorear el estado de la memoria y el uso de la misma por parte de los procesos que corren en un server (digamos, los datos que se obtienen con el comando "top") en unos servidores remotos que corren CentOS.
Y, además, necesito saber cuántas peticiones está atendiendo un Apache, que hospeda una web, en función del tiempo (también sobre CentOS).
¿Es posible hacer esto con Nagios? ¿De qué manera?
En este momento tengo Nagios funcionando sin problemas, y monitoriza los siguientes servicios: "Current Load", "Disk Space", "HTTP" y "Total Processes", usando los plugins que vienen (lo tengo funcionando sobre un Debian 6.0)
Estos datos están buenos, pero no responden a mis requerimientos :( ¿Cómo puedo monitorizar los servicios antes explicados?
Gracias de entemano!
Hola Ivan, antes de todo.. excelente post.
Tengo un consulta. Quiero saber la cantidad de impresiones de cada cliente Windows por medio de SNMP o el cliente NSClient++ instalado en ellos.
Sabes si es posible esto?
Muchas gracias.
Hola Ivan,
El post una pasada!! Me ha ayudado mucho.
¿Hay Alguna foma de ponerme en contacto contigo por mail?
Un saludo y muchas gracias
Hola Nacho,
me alegro de que te haya gustado el post. Gracias :-)
He añadido en la barra lateral de la derecha mi email de contacto. Lo había hecho hace tiempo pero se debió perder en alguna actualización del blog.
Saludos, Iván.
Hola Ivan. Son muy nueva en linux y en Nagios tambien e tenido algunos problemas por que no puedo configurar la plataforma. Algún consejo por fis. Estoy huy desesperada.
Hola Sandy,
este artículo tiene ya más de 6 años, por lo que es altamente probable que lo que cuento ya no aplique porque tanto Nagios como Linux han evolucionado mucho.
Además ten en cuenta que el sistema operativo del que hablo es Solaris y no Linux.
Saludos, Iván.
hola amigos,
necesito ayuda, tengo un centreon sobre nagios monitorizando una red en producción y en las gráficas solo se muestra información cada hora en punto 12, 1, 2, 3...etc. Tengo monitorizado el ancho de banda y las gráficas se muestran muy descompensadas porque el lapso de tiempo es demasiado largo, como digo solo actualizadas cada hora. Mi pregunta es ¿que es lo que tengo que hacer para que las gráficas se actualicen en vez de cada hora cada 5 minutos?. Muchísimas gracias de antemano.
Publicar un comentario