Lo prometido es deuda y aquí continúo con la última parte del análisis de VMware ESX Server.
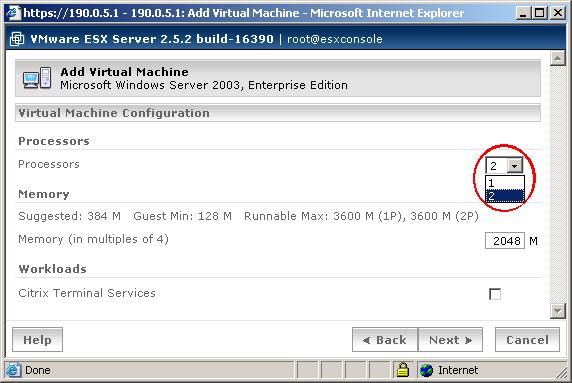
Una de las primeras dificultades que encontré fue aumentar el número de CPUs en las máquinas virtuales. Cuando creamos una máquina virtual con el asistente podemos elegir el número de CPUs virtuales (vcpus) entre 1 y 2 en función del sistema operativo. Así, con Windows 2003 Server el máximo es 2 y con Windows XP es 1. En seguida encontré cómo aumentar esto ya que como habéis visto en las capturas del
artículo anterior, el servidor Windows 2003 tiene asignadas 4 CPUs. Para ello, en la consola de administracción, seleccionamos la máquina virtual que nos interese para ver todas sus opciones. Nos vamos al menú
Options y en
Verbose Options, añadimos la propiedad
numvcpus con el valor que deseemos. En las máquinas virtuales con Windows XP he dejado sólo una y en Windows 2003 Server cuatro. El resultado es:
Veamos un poco más de cerca el linux instalado que se encarga de gestionar todo:
[root@esxconsole root]# uname -a
Linux esxconsole 2.4.9-vmnix2 #1 Thu Sep 8 14:46:53 PDT 2005 i686 unknown
[root@esxconsole root]# vdf -h
Filesystem Size Used Avail Use% Mounted on
/dev/cciss/c0d0p2 2.4G 866M 1.4G 38% /
/dev/cciss/c0d0p1 50M 12M 36M 25% /boot
none 188M 0 187M 0% /dev/shm
vmhba2:0:0:6 200G 62G 138G 30% /vmfs/vmhba2:0:0:6
Como ya nos comentó Supercoco en los comentarios del anterior artículo se trata de un kernel linux (en este caso 2.4). Justo "encima" de este kernel linux se ejecuta un
vmkernel que se encarga de proporcionar todas las funciones de virtualización como por ejemplo el comando
vdf anterior para mostrar los filesystems virtuales.
El sistema de ficheros VMFS es el que está montado en
/vmfs/vmhba2:0:0:6 y es donde se almacenan las máquinas virtuales. A diferencia de otras versión de VMware como la Server o la Workstation, en la versión ESX se reserva en el disco toda la capacidad que queramos dar a los discos duros de las máquinas virtuales. Así, aunque después de instalar el sistema operativo en la máquina virtual sólo tengamos ocupados un par de Gbytes, habremos "perdido" el espacio total del disco.
[root@esxconsole root]# ls -lh /vmfs/vmhba2\:0\:0\:6/
-rw------- 1 root root 20G Nov 13 10:28 W2K3_DiskC.vmdk
-rw------- 1 root root 5.0G Nov 13 10:28 W2K3_DiskE.vmdk
-rw------- 1 root root 7.9G Nov 7 09:48 SwapFile.vswp
-rw------- 1 root root 15G Nov 13 10:25 WXP_Client1_DiskC.vmdk
Esta máquina está en una plataforma de pruebas junto con otras 20 que utilizamos en conjunto para probar todas las opciones de la aplicación. Después de instalar unas cuantas versiones, poner parches y demás, las instalaciones de las máquinas se quedan un poco "tocadas". Para evitar estar reinstalando tenemos hechas unas imagenes con
Acronis True Image y de vez en cuando restauramos las máquinas al estado inicial. Hacer esto con VMware es tan fácil como apagar la máquina virtual y ejecutar:
[root@esxconsole vmhba2:0:0:6]# gzip -c W2K3_DiskC.vmdk > W2K3_DiskC_CLON.vmdk.gz
[root@esxconsole vmhba2:0:0:6]# ls -lh
-rw------- 1 root root 20G Nov 13 10:28 W2K3_DiskC.vmdk
-rw------- 1 root root 1.7G Nov 8 16:44 W2K3_DiskC_CLON.vmdk.gz
Y después, cuando queramos recuperar la máquina, simplemente descomprimimos el archivo .gz y tenemos la máquina restaurada en muy poco tiempo.
Otro de los aspectos a tener en cuenta es la instalación de Windows XP. Según se nos indica cuando seleccionamos la creación de una máquina virtual con dicho sistema operativo, necesitamos descargar los
drivers SCSI de la web de WMware para que la instalación de Windows XP reconozca nuestro disco duro virtual. Es una imagen de disquete y para utilizarla tenemos que montar una disquetera virtual en la instalación y decirle que utilice dicha imagen.
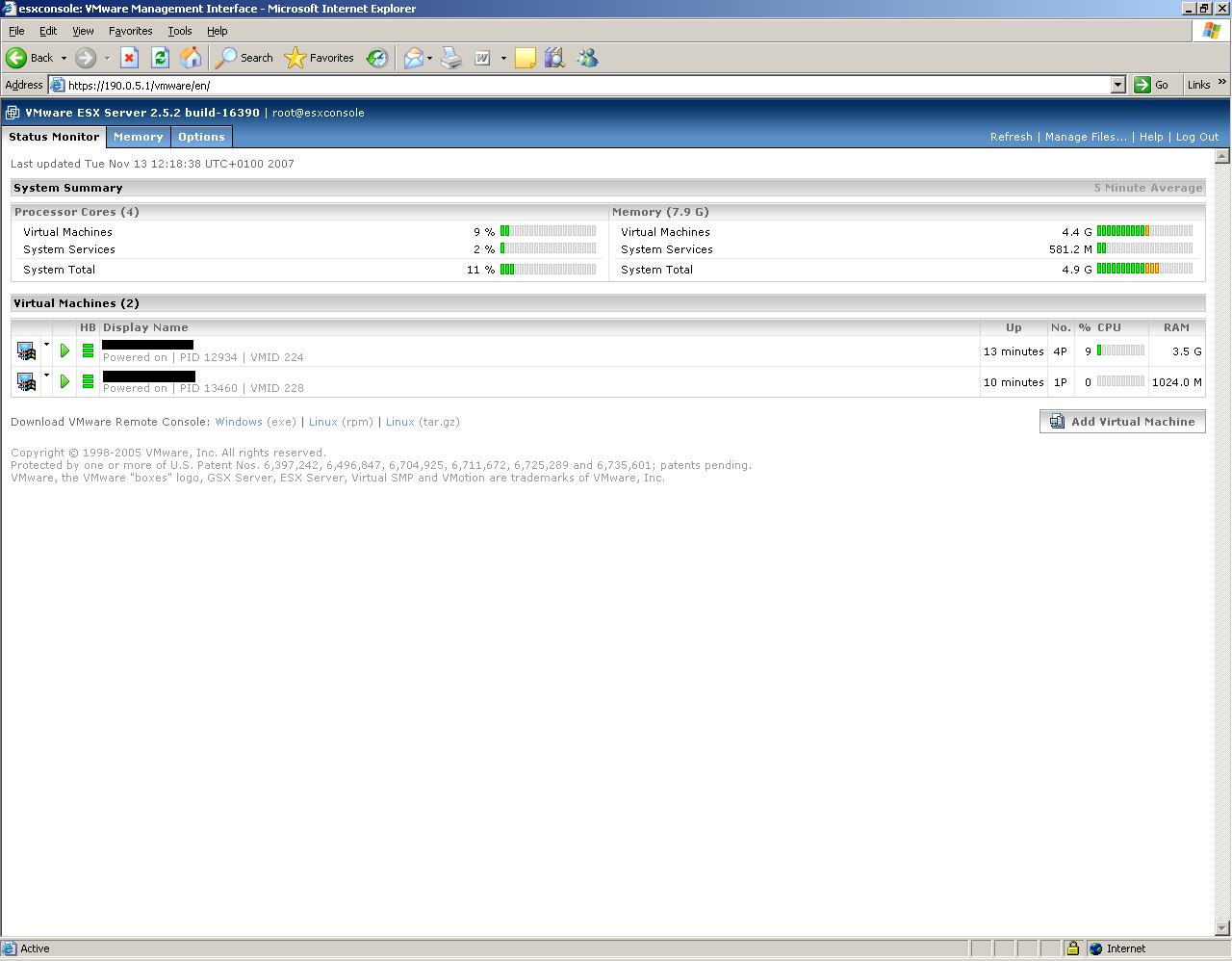
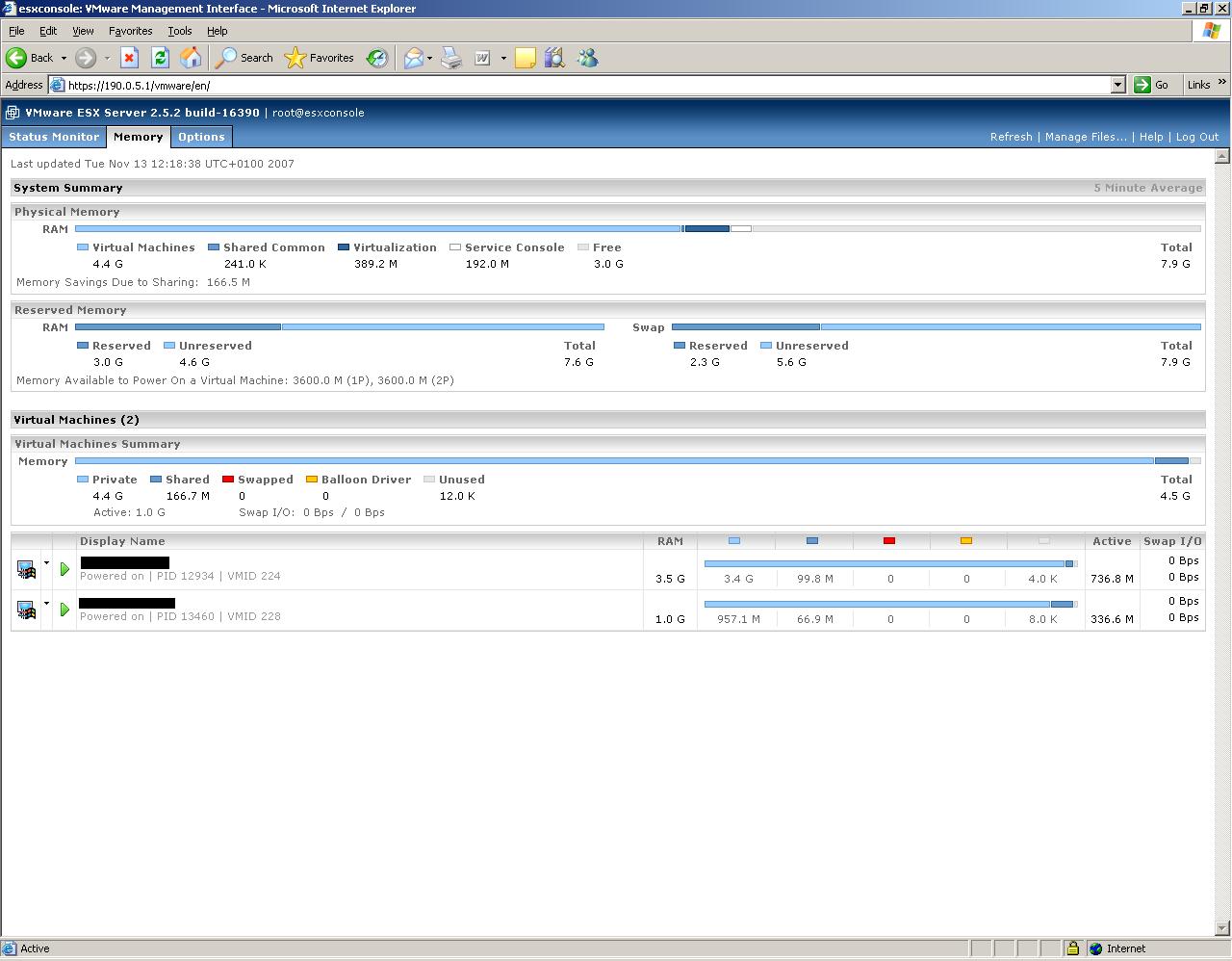
Todo el sistema se controla desde una interfaz gráfica que está muy cuidada y que muestra gran cantidad de información de las máquinas virtuales. Así, podemos tener una visión general de las máquina virtuales que están en ejecución, su consumo de memoria, cpu, el tiempo que llevan en funcionamiento,...
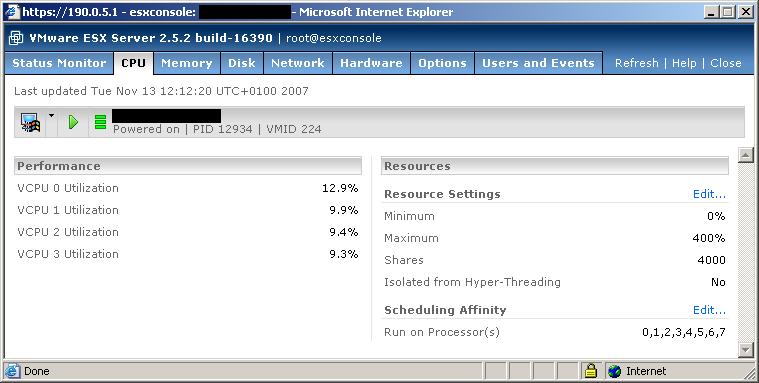
Luego, si seleccionamos una máquina virtual concreta podemos tener estadísticas más detalladas de la utilización de las CPUs, acceso al disco o la red, podemos controlar en qué CPUs físicas queremos ejecutar la máquina virtual,... y así un gran número de opciones.
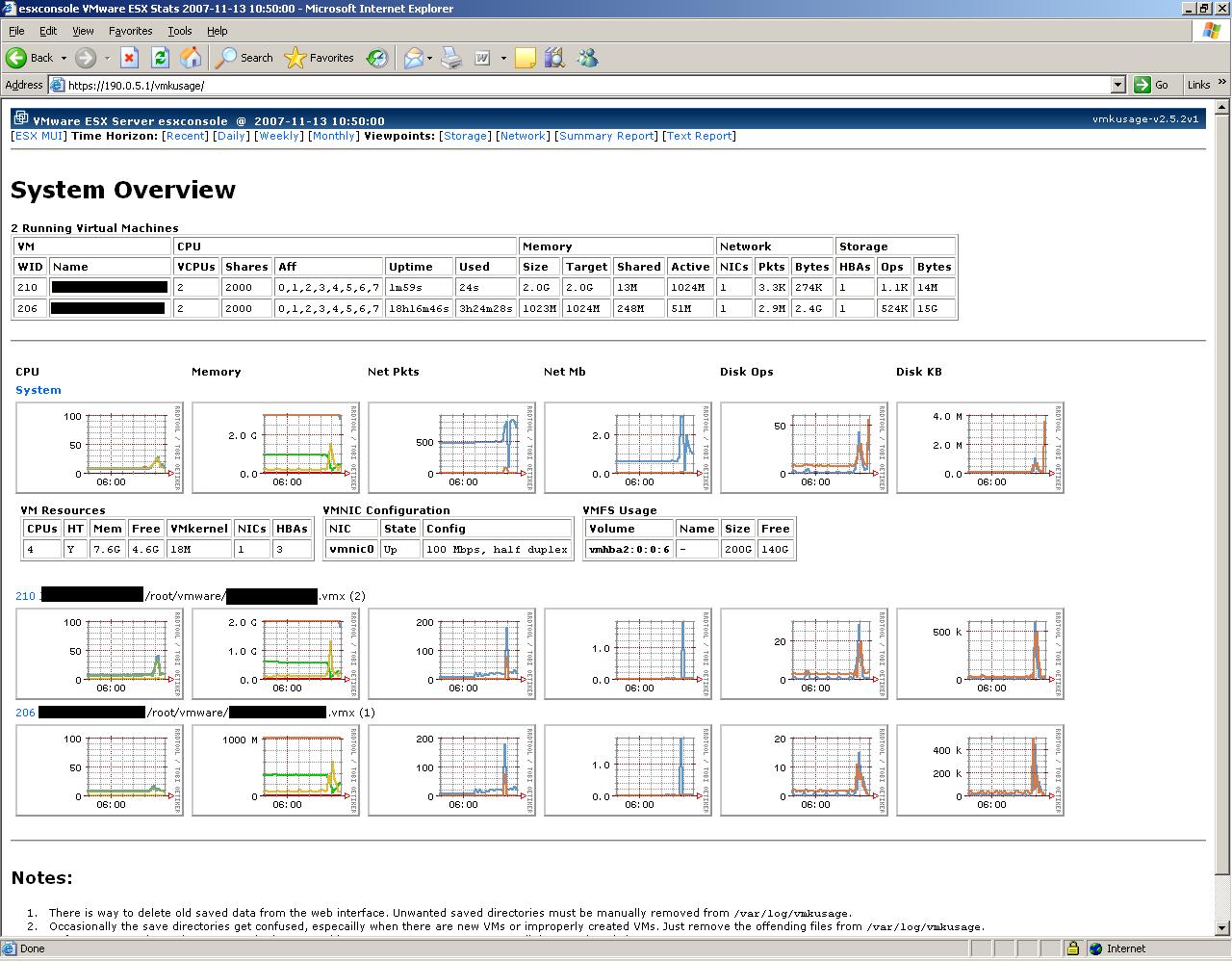
Otra de las opciones que posee VMware ESX es una web de estadísticas en la que podemos ver el estado de las máquinas virtuales, el consumo de CPU, disco duro, ancho de banda,... a lo largo del tiempo. Para activarlas simplemente ejecutamos:
[root@esxconsole root]# vmkusagectl install
Info: Adding cron job
Con lo que cada minuto se ejecutará por crontab el script que recolecta las estadísticas y a través del navegador web podemos analizarlas. Podemos tener una visión general del estado del sistema o centrarnos en una máquina virtual concreta, ver el estado por día, semana,...
Además de todo lo anterior, también podemos exportar e importar las máquinas virtuales al formato de las versiones Server/Workstation:
[root@esxconsole vmhba2:0:0:6]# vmkfstools -e ExportVM.vmdk vmhba2:0:0:6:WXP_Client1_DiskC.vmdk
Exporting disk vmhba2:0:0:6:WXP_Client1_DiskC.vmdk:
Export: 100% done.
[root@esxconsole vmhba2:0:0:6]# ls -lh ExportVM*
-rw------- 1 root root 1.6G Nov 22 09:17 ExportVM-s001.vmdk
-rw------- 1 root root 1.0G Nov 22 09:17 ExportVM-s002.vmdk
-rw------- 1 root root 1.1G Nov 22 09:17 ExportVM-s003.vmdk
-rw------- 1 root root 2.0G Nov 22 09:17 ExportVM-s004.vmdk
-rw------- 1 root root 912M Nov 22 09:17 ExportVM-s005.vmdk
-rw------- 1 root root 2.0G Nov 22 09:17 ExportVM-s006.vmdk
-rw------- 1 root root 1.5G Nov 22 09:17 ExportVM-s007.vmdk
-rw------- 1 root root 1.2M Nov 22 09:17 ExportVM-s008.vmdk
-rw------- 1 root root 614 Nov 22 09:17 ExportVM.vmdk
Finalmente para terminar decir que de momento todo funciona muy bien y estoy muy contento con la oportunidad de haber podido cacharrear con este producto. Soy un fanático de la virtualización y desde las primeras versiones de VMware Workstation tanto para windows como para linux estoy utilizando el producto y me encanta. El futuro es la virtualización porque cada vez tenemos máquinas más potentes a precios más bajos. Evidentemente, en este caso particular de virtualizar máquinas windows, siempre necesitamos otro equipo para conectarnos a través de la consola e interactuar con la máquina virtual. Esto no ocurriría si instalasemos máquinas virtuales linux ya que sólo necesitaríamos acceso por ssh. Aún así, se de primera mano que en grandes empresas se utiliza para virtualizar servidores windows en máquinas Blade.