Desde siempre me ha gustado programar, especialmente en Java. Mi principal problema es que siempre me he centrado en el back office y nunca me he preocupado por las interfaces de usuario. Así, si en algún momento se me ocurría hacer alguna aplicación para algo en concreto, al final desistía porque no iba a ser capaz de hacer una interfaz de usuario decente.
Hace unos meses que he descubierto Google Web Toolkit y me parece increíble. Para el que no lo conozca son unas librerías de Google para programar aplicaciones web 2.0 pero todo desde Java. Tanto el desarrollo como la depuración la hacemos desde Eclipse y cuando queremos desplegar nuestra aplicación lo que se hace automáticamente es convertir ese código Java a Javascript (Ajax). Además, tenemos la ventaja de que se crean automáticamente distintas versiones de la aplicación para los distintos navegadores y no nos tenemos que preocupar de esos pequeños hacks que siempre hay que hacer para que funcione en internet explorer, firefox, opera... Cuando nos conectamos a la web que hemos creado, ésta detecta automáticamente el navegador utilizado y nos sirve la web necesaria.
La manera que recomiendo para comenzar con GWT es ir a la Developer's Guide y seguir paso a paso el tutorial que Google ha creado. Es todo muy intuitivo y fácil de seguir y se explica cómo crear una aplicación de ejemplo desde cero. Además se empieza con lo más básico y poco a poco se va añadiendo nueva funcionalidad.
Yo le he cogido el gustillo y estoy desarrollando una aplicación web de la que hablaré en próximos posts.
miércoles, 17 de diciembre de 2008
lunes, 15 de diciembre de 2008
El regalo friki de este año
Aunque lo pongo con una semana de retraso, este es el regalo friki que me ha hecho mi mujer este año para mi cumpleaños. Un Potato Vader:
La única pega es que lo voy a tener que compartir porque a Judith también le ha gustado y de vez en cuando me lo pide y se lo pasa genial poniéndole y quitándole la nariz, orejas, lengua,...
 |
La única pega es que lo voy a tener que compartir porque a Judith también le ha gustado y de vez en cuando me lo pide y se lo pasa genial poniéndole y quitándole la nariz, orejas, lengua,...
martes, 9 de diciembre de 2008
Cuanto hijo de puta suelto...
NOTA: Perdón por el post (y por el vocabulario) puesto que no viene a cuento con el blog, es totalmente personal y realmente sólo me sirve para descargar y desahogarme, pero en fin...
Pues nada, que resulta que este fin de semana, para celebrar mi cumpleaños íbamos a ir al teatro. Cometí el error de entrar demasiado en Madrid con el coche en lugar de dejarlo aparcado en las afueras y coger el metro. Después del atasco y demás ya íbamos con la hora un poco pillada y andando entre la gente o parado en algún semaforo me abrieron el bolso y me robaron la PDA y la iPod :-(. Lo que más me jode fue que pasó en menos de 5 minutos y cuando me di cuenta ya era tarde. Algún hijo de puta fue detrás mío y en cuanto vio la oportunidad, zas!, me cazó. La cartera y el móvil se salvaron, pero el daño ya estaba hecho.
Lo peor de todo es que la PDA no la va a poder utilizar nadie porque está configurada para que haya que desbloquearla cada vez que se encienda y ni siquiera con un hard-reset se puede eliminar esta protección. Además, no lleva clave sino que va por huella dactilar, así que nada, la tirarán y no podrán usarla. Respecto a la iPod, esta sí la podrán usar o revender en ebay o donde sea... Respecto a la información de las tarjetas de memoria de la PDA, lo único crítico es el archivo de claves del KeePass, que aunque es muy complicado de romper, nunca se sabe, así que ya he cambiado todas las claves y listo, no hay mayor problema.
Mira que siempre tengo cuidado con todo esto, pero ya se sabe que las prisas nunca son buenas compañeras...
Pues nada, que resulta que este fin de semana, para celebrar mi cumpleaños íbamos a ir al teatro. Cometí el error de entrar demasiado en Madrid con el coche en lugar de dejarlo aparcado en las afueras y coger el metro. Después del atasco y demás ya íbamos con la hora un poco pillada y andando entre la gente o parado en algún semaforo me abrieron el bolso y me robaron la PDA y la iPod :-(. Lo que más me jode fue que pasó en menos de 5 minutos y cuando me di cuenta ya era tarde. Algún hijo de puta fue detrás mío y en cuanto vio la oportunidad, zas!, me cazó. La cartera y el móvil se salvaron, pero el daño ya estaba hecho.
Lo peor de todo es que la PDA no la va a poder utilizar nadie porque está configurada para que haya que desbloquearla cada vez que se encienda y ni siquiera con un hard-reset se puede eliminar esta protección. Además, no lleva clave sino que va por huella dactilar, así que nada, la tirarán y no podrán usarla. Respecto a la iPod, esta sí la podrán usar o revender en ebay o donde sea... Respecto a la información de las tarjetas de memoria de la PDA, lo único crítico es el archivo de claves del KeePass, que aunque es muy complicado de romper, nunca se sabe, así que ya he cambiado todas las claves y listo, no hay mayor problema.
Mira que siempre tengo cuidado con todo esto, pero ya se sabe que las prisas nunca son buenas compañeras...
viernes, 17 de octubre de 2008
Colaborando en un proyecto de Software Libre
Así dicho, con el título del post parece que estoy colaborando en el desarrollo del kernel de Linux o algo similar. Nada más lejos de la realidad. A un amigo, Jose, le apetecía cacharrear un poco con las APIs de Google, y aprovechando que trabaja con Java, Spring, Hibernate y MySQL se hizo una pequeña aplicación Java para sincronizar sus contactos de Gmail (y toda su información asociada) a una base de datos local MySQL utilizando dicha tecnología. Además, decidió publicar el código en Google Code, en donde Google proporciona un SVN para subir el código, un Wiki e incluso un gestor de incidencias. El resultado lo podéis ver en la web del proyecto GDataUtils (así es como lo llamó). El proyecto está liberado con la GPLv3.
Como sabe que a mi me gustan estas cosas y tenía ganas de que me enganchara, me contó en un par de horas cómo funciona Hibernate y Spring y cómo configurarlo para que yo pudiera comenzar la parte de la sincronización de Google Calendar (aprovechando que ya conocía un poco el API de Google Calendar).
Para el que no lo conozca o haya programado en Java picándose a mano las queries contra la base de datos, utilizar Spring + Hibernate es simplemente magnífico. Todo son objetos y por ejemplo insertar en una tabla es crear un objeto que representa a esa tabla, hacer set() de los campos y salvar ese objeto. Automágicamente nuestro objeto se salva en la base de datos. Las búsquedas también son muy simples y si todo lo haces bien en el código java no verás ni una sola sentencia sql. Es realmente cómodo programar así, y aunque en un principio cuesta acostumbrarse y hay bastante fallos debido a la configuración de Spring y Hibernate, una vez que le coges el truco el desarrollo es muy rápido.
Respecto al código, la parte de sincronización de los contactos (desde Google a la base de datos Local) la terminó Jose hace tiempo y funciona muy bien. Además se guarda un log con todas las modificaciones que se realizan por si es necesario volver atrás. Respecto a mi parte de la sincronización de los calendarios y eventos, está casi terminada aunque todavía sin log. El problema es que tengo este proyecto parado desde hace algún tiempo puesto que ahora estoy centrado en otro que os contaré en breve.
Por supuesto la aplicación al estar programada en Java es multiplataforma. De hecho Jose programa desde Windows y yo desde Linux y ninguno de los dos hemos tenido problemas con el código del otro.
Si alguno se anima a probarlo os doy los pasos que debéis seguir para configurar todo. El entorno de desarrollo, como no podía ser de otra forma es Eclipse, aunque recomiendo instalar EasyEclipse puesto que incluye un montón de plugins y configuraciones que nos harán la vida más fácil.
Instalar MySql 5: Desde linux es tan sencillo como hacer $ sudo apt-get install mysql-server-5.0 mysql-client-5.0. Instalar ant: En EasyEclipse ya está incluído. Crear en mysql un esquema que se llame gdata (o como queramos) y que esté vacío. Configurar el repositorio SVN del proyecto y hacer el checkout. En la web del proyecto tenéis información sobre cómo configurar el repositorio. Además, podéis navegar por la estructura de directorios y archivos y ver los últimos cambios que se han hecho. Editar el archivo config/hibernate.properties y cambiar los parámetros de la conexión a mysql. Editar el archivo config/SpringConfiguration.xml y añadir el nombre de usuario (con @gmail.com) y password para poder acceder a la cuenta de Google. Esta información sólo se utiliza para conectarse a Google y obtener los contactos. No se almacena en ningún sitio y por supuesto nosotros no tenemos acceso a ella. De todas formas el código está ahí para que veáis lo que se hace con esa información. Ventajas de publicar el código :-P. Ejecutar la tarea ant createSchema que se encarga de crear las tablas necesarias en la base de datos. Ejecutar la tarea ant distrib: Creará el directorio target en el que se encuentra la aplicación ya compilada y lista para su ejecución. En target/distrib ejecutar la tarea ant SyncFromGData. Y listo, mirar la base de datos y examinar la copia de tus contactos.
Dicho así, la verdad es que parece muy complicado (a mi me lo pareció la primera vez), pero luego, una vez que lo haces ves que es sencillo. Además, la mayoría de las tareas sólo es necesario ejecutarlas una vez. Puedes lanzar sucesivamente la sincronización puesto que comprueba si los datos ya se han descargado para no duplicarlos. Además, también actualiza los cambios que hagamos en los contactos.
Si queréis ejecutar la sincronización de calendarios y eventos el proceso es similar (muchos pasos no hay que repetirlos) y sólo tendréis que cambiar la última tarea ant por la de GoogleCalendar.
Aunque todo esto así parezca que no es útil y que no tiene mucho sentido, a mi me ha servido para conocer Spring y Hibernate, me ha abierto un mundo nuevo que desconocía y me he actualizado porque como he dicho alguna vez me quedé en Java 1.4.2 y hacía bastante que no programaba en serio.
Lo realmente interesante de todo es que está realizado completamente con software libre: Google proporciona el SVN para el código, Spring, Hibernate, MySql, Eclipse... Todo es software libre. Además en mi caso, con Linux, hasta el sistema operativo. Lo único que quedaba era Java y hace ya algún tiempo que Sun lo liberó con licencia GPLv2.
Si alguien se anima a desarrollar la sincronización de GoogleReader, GoogleNotebook,... lo que sea, que me lo diga y vemos cómo empezar.
¿Alguna duda?
Como sabe que a mi me gustan estas cosas y tenía ganas de que me enganchara, me contó en un par de horas cómo funciona Hibernate y Spring y cómo configurarlo para que yo pudiera comenzar la parte de la sincronización de Google Calendar (aprovechando que ya conocía un poco el API de Google Calendar).
Para el que no lo conozca o haya programado en Java picándose a mano las queries contra la base de datos, utilizar Spring + Hibernate es simplemente magnífico. Todo son objetos y por ejemplo insertar en una tabla es crear un objeto que representa a esa tabla, hacer set() de los campos y salvar ese objeto. Automágicamente nuestro objeto se salva en la base de datos. Las búsquedas también son muy simples y si todo lo haces bien en el código java no verás ni una sola sentencia sql. Es realmente cómodo programar así, y aunque en un principio cuesta acostumbrarse y hay bastante fallos debido a la configuración de Spring y Hibernate, una vez que le coges el truco el desarrollo es muy rápido.
Respecto al código, la parte de sincronización de los contactos (desde Google a la base de datos Local) la terminó Jose hace tiempo y funciona muy bien. Además se guarda un log con todas las modificaciones que se realizan por si es necesario volver atrás. Respecto a mi parte de la sincronización de los calendarios y eventos, está casi terminada aunque todavía sin log. El problema es que tengo este proyecto parado desde hace algún tiempo puesto que ahora estoy centrado en otro que os contaré en breve.
Por supuesto la aplicación al estar programada en Java es multiplataforma. De hecho Jose programa desde Windows y yo desde Linux y ninguno de los dos hemos tenido problemas con el código del otro.
Si alguno se anima a probarlo os doy los pasos que debéis seguir para configurar todo. El entorno de desarrollo, como no podía ser de otra forma es Eclipse, aunque recomiendo instalar EasyEclipse puesto que incluye un montón de plugins y configuraciones que nos harán la vida más fácil.
Dicho así, la verdad es que parece muy complicado (a mi me lo pareció la primera vez), pero luego, una vez que lo haces ves que es sencillo. Además, la mayoría de las tareas sólo es necesario ejecutarlas una vez. Puedes lanzar sucesivamente la sincronización puesto que comprueba si los datos ya se han descargado para no duplicarlos. Además, también actualiza los cambios que hagamos en los contactos.
Si queréis ejecutar la sincronización de calendarios y eventos el proceso es similar (muchos pasos no hay que repetirlos) y sólo tendréis que cambiar la última tarea ant por la de GoogleCalendar.
Aunque todo esto así parezca que no es útil y que no tiene mucho sentido, a mi me ha servido para conocer Spring y Hibernate, me ha abierto un mundo nuevo que desconocía y me he actualizado porque como he dicho alguna vez me quedé en Java 1.4.2 y hacía bastante que no programaba en serio.
Lo realmente interesante de todo es que está realizado completamente con software libre: Google proporciona el SVN para el código, Spring, Hibernate, MySql, Eclipse... Todo es software libre. Además en mi caso, con Linux, hasta el sistema operativo. Lo único que quedaba era Java y hace ya algún tiempo que Sun lo liberó con licencia GPLv2.
Si alguien se anima a desarrollar la sincronización de GoogleReader, GoogleNotebook,... lo que sea, que me lo diga y vemos cómo empezar.
¿Alguna duda?
jueves, 9 de octubre de 2008
El injusto canon de los discos duros y cómo evitarlo
Como comenté el otro día, he ampliado el raid 1 de mi servidor de backup puesto que se me estaba quedando pequeño. Cuando me puse a buscar discos duros tenía en mente gastarme como mucho 55-60€ por disco duro. Al principio miré en la web de PcBox puesto que me parece que tienen buenos precios y he comprado bastante hardware y nunca he tenido problemas. Mi sorpresa vino al ver el precio del mismo modelo de disco duro:
Como podéis ver, es exactamente el mismo modelo de disco duro pero con una diferencia entre el maestro y el esclavo de 21,03€. Según se aprobó, el canon para los discos duros es de 12€ + IVA (13,92€) y éste no se aplica a los llamados discos duros maestros (los que vienen de fábrica instalados en el ordenador). Llamé por teléfono a PcBox y pregunté si podía comprar 2 discos duros maestros para pagar menos por ellos y la respuesta del dependiente fue: "Sí, no hay problema, siempre que me compres los dos ordenador completos. Sino, te los tengo que cobrar a precio de disco esclavo". Además, me parece que PcBox quiere hacer más negocio con los discos duros porque en lugar de subirles el precio 13,92€ se lo ha subido 21,03€ y supongo que la diferencia se la quedan ellos.
Obviamente pagar por algo que cuesta 55€ casi 14€ más (¡¡un 25% del precio!!) para que Ramoncín, Tedy y demás gente de esa calaña sigan viviendo del cuento, no me parecía normal, así que busqué otras alternativas. Hablando con algunos compañeros y buscando un poco se pueden encontrar tiendas en la red donde todavía venden discos duros sin canon. Además, pude hacer la reserva por teléfono y acercarme a recoger el disco en mano pagando sólo el coste del disco. En mi caso cada disco costó 57,5€ y en total me gasté 115€ frente a los 155€ que me habría gastado en PcBox. Así que ya sabéis, si queréis ampliar el hardware buscad un poco puesto que os podéis ahorrar una buena cantidad de euros que no van a la saca de los de siempre...
 |
Como podéis ver, es exactamente el mismo modelo de disco duro pero con una diferencia entre el maestro y el esclavo de 21,03€. Según se aprobó, el canon para los discos duros es de 12€ + IVA (13,92€) y éste no se aplica a los llamados discos duros maestros (los que vienen de fábrica instalados en el ordenador). Llamé por teléfono a PcBox y pregunté si podía comprar 2 discos duros maestros para pagar menos por ellos y la respuesta del dependiente fue: "Sí, no hay problema, siempre que me compres los dos ordenador completos. Sino, te los tengo que cobrar a precio de disco esclavo". Además, me parece que PcBox quiere hacer más negocio con los discos duros porque en lugar de subirles el precio 13,92€ se lo ha subido 21,03€ y supongo que la diferencia se la quedan ellos.
Obviamente pagar por algo que cuesta 55€ casi 14€ más (¡¡un 25% del precio!!) para que Ramoncín, Tedy y demás gente de esa calaña sigan viviendo del cuento, no me parecía normal, así que busqué otras alternativas. Hablando con algunos compañeros y buscando un poco se pueden encontrar tiendas en la red donde todavía venden discos duros sin canon. Además, pude hacer la reserva por teléfono y acercarme a recoger el disco en mano pagando sólo el coste del disco. En mi caso cada disco costó 57,5€ y en total me gasté 115€ frente a los 155€ que me habría gastado en PcBox. Así que ya sabéis, si queréis ampliar el hardware buscad un poco puesto que os podéis ahorrar una buena cantidad de euros que no van a la saca de los de siempre...
jueves, 2 de octubre de 2008
Ampliando un raid 1 en linux
Resulta que el raid 1 que monté en mi servidor de backup estaba al 96% de sus escasos 60GB. De hecho, la última vez que lancé el backup se me llenó y tuve que estar borrando archivos y arreglando el estropicio a mano.
Así, me decidí por un par de discos de 320GB y el pasado fin de semana estuve haciendo el cambio. El proceso es muy sencillo y no tiene ningún truco ni paso especial que haya que realizar. Como ya he puesto varios tutoriales sobre el raid 1, lo único que voy a comentar son los pasos que seguí por si alguien necesita ampliar el suyo pero sin mucho detalle. Para información adicional os remito al artículo original del raid 1 en linux.
Conectar los discos y particionarlos.
Crear el nuevo dispositivo del raid. Como el raid anterior era /dev/md0, este nuevo será /dev/md1. Armarse de paciencia mientras dura la creación del raid. En mi caso fueron más de 2 horas.
Formatear el raid y montarlo en un nuevo directorio. Fijaos en el tamaño disponible para datos. De los 294GB teóricos, sólo 279GB están disponibles, el resto están reservados para los metadatos e información necesaria del raid 1.
Copiar todos los datos del antiguo raid al nuevo. Es necesario asegurarse de que no hay ningún proceso en ejecución que pueda modificar los datos mientras los copiamos. En casa es sencillo, pero en entornos con más usuarios habría que denegar las conexiones entrantes o restringirlas de alguna forma.
Como paso final, es necesario actualizar los archivos /etc/fstab y /etc/mdadm/mdadm.conf con la información del nuevo raid y eliminar las entradas correspondientes al antiguo.
Una vez hecho lo anterior podemos apagar la máquina, desconectar los discos duros antiguos y arrancar de nuevo. Si todo ha ido bien, el sistema debería arrancar sin mostrar ningún error y en el mismo punto de montaje deberíamos tener disponible el nuevo raid. Ahora ya sólo nos queda empezar a llenar de nuevo el raid y dentro de dos o tres años repetir el tutorial pero esta vez con discos duros de un par de teras... ;-).
shian:~# df -h
S.ficheros Tamaño Usado Disp Uso% Montado en
/dev/md0 56G 50G 2,6G 96% /mnt/raid
Así, me decidí por un par de discos de 320GB y el pasado fin de semana estuve haciendo el cambio. El proceso es muy sencillo y no tiene ningún truco ni paso especial que haya que realizar. Como ya he puesto varios tutoriales sobre el raid 1, lo único que voy a comentar son los pasos que seguí por si alguien necesita ampliar el suyo pero sin mucho detalle. Para información adicional os remito al artículo original del raid 1 en linux.
shian:~# fdisk -l
Disk /dev/hdf: 320.0 GB, 320072933376 bytes
255 heads, 63 sectors/track, 38913 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Disk /dev/hdf doesn't contain a valid partition table
Disk /dev/hdh: 320.0 GB, 320072933376 bytes
255 heads, 63 sectors/track, 38913 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Disk /dev/hdh doesn't contain a valid partition table
shian:~# mdadm --create /dev/md1 --verbose --level=1 --raid-devices=2 /dev/hdf1 /dev/hdh1
mdadm: size set to 312568576K
mdadm: array /dev/md1 started.
shian:~# cat /proc/mdstat
Personalities : [raid1]
md1 : active raid1 hdh1[1] hdf1[0]
312568576 blocks [2/2] [UU]
[>....................] resync = 0.0% (182272/312568576) finish=142.7min speed=36454K/sec
shian:~# mkfs.ext3 /dev/md1
shian:~# mkdir /mnt/raid_new
shian:~# mount /dev/md1 /mnt/raid_new/
shian:~# df -h
S.ficheros Tamaño Usado Disp Uso% Montado en
/dev/md0 56G 50G 2,6G 96% /mnt/raid
/dev/md1 294G 191M 279G 1% /mnt/raid_new
shian:~# cp -a /mnt/raid /mnt/raid_new
shian:~# df -h
S.ficheros Tamaño Usado Disp Uso% Montado en
/dev/md0 56G 50G 2,6G 96% /mnt/raid
/dev/md1 294G 50G 230G 17% /mnt/raid_new
Una vez hecho lo anterior podemos apagar la máquina, desconectar los discos duros antiguos y arrancar de nuevo. Si todo ha ido bien, el sistema debería arrancar sin mostrar ningún error y en el mismo punto de montaje deberíamos tener disponible el nuevo raid. Ahora ya sólo nos queda empezar a llenar de nuevo el raid y dentro de dos o tres años repetir el tutorial pero esta vez con discos duros de un par de teras... ;-).
sábado, 13 de septiembre de 2008
Porqué nunca utilizaré windows vista
Empezamos por el final y luego hacemos un flashback y cuento la historia completa. No pienso utilizar windows vista nunca. En mi casa no va a haber un ordenador con ese "sistema operativo" (si se le puede llamar así sin menospreciar al resto de sistemas operativos que sí lo son).
Resulta que el portatil de mi padre dijo basta y me encargó la tarea de buscarle uno nuevo que no fuera muy caro y que no tuviera que actualizar en mucho tiempo. Después de mucho buscar encontré una oferta muy buena (más de 500EUR de ahorro) por un Dell XPS 1530 con unas características muy completas. La única pega, como no, el sistema operativo: Windows Vista. Mi padre me dejó el portatil durante una semana para probarlo y darle caña a ver qué tal se comportaba y en cuanto a hardware la verdad es que me ha encantado. Pero eso sí, en menos de una semana he terminado asqueado de windows vista. A continuación voy a poner mis impresiones sobre el sistema operativo:
Velocidad apagado/arranque: Una de las cosas que leí cuando salió Vista al mercado es que la velocidad de arranque y apagado se había mejorado respecto a XP. La verdad es que la primera vez que lo apagué y encendí me dió una sensación muy buena, pero luego todo se esfumó. Por defecto, cuando pulsamos en el icono de apagar, lo que realmente estamos haciendo es hibernando el equipo. Si queremos apagarlo completamente tenemos que seleccionar la opción concreta en el menú de opciones de apagado. Es una buena jugada por parte de Micro$oft: En el botón que va a pulsar el 95% de los usuarios en lugar de poner la opción de apagar el equipo, ponemos la de hibernar, y así parece que apaga y enciendo muy rápido. Usando la opción de hibernar, hasta mi antiguo Pentium 2 apagaba y arrancaba rápido. Así que, señores de Micro$oft, no nos vendan la moto. Actualizaciones de seguridad: Como comenté el año pasado, en el pueblo hay una conexión wifi gratuita. Una de las mañanas en las que estaba en el parque leyendo el correo y los feeds, windows vista se descargó 24 actualizaciones de seguridad. Luego por la tarde, ya en casa, al apagar el equipo me pidió confirmación para instalarlas. Tardó más de 20 minutos en hacerlo. Pero ahí no acaba la cosa. Por la noche, cuando encendí de nuevo el portatil terminó de configurar las actualizaciones y reinició dos veces la máquina. En total fueron casi 10 minutos de reloj con cara de tonto delante del portatil sin poder hacer nada. Service Pack 1: Ya de vuelta a casa, la actualización del Service Pack 1 fue tremenda, prefiero ni contar lo que tardó. Confirmaciones: Otra de las supuestas novedades de windows vista es que gestiona mejor los permisos y la seguridad. Sinceramente creo que se han pasado. Aparecen confirmaciones para ejecutar programas, instalarlos, borrar archivos, desinstalar programas,... Después de un rato de uso ya ni leía los mensajes y siempre aceptaba las acciones. Sé que se puede deshabilitar, pero entonces pierde toda su gracia y no estamos tan "protegidos". Lentitud en el procesado de archivos: Aunque es un problema ya conocido, lo noté especialmente al preparar el portatil para llevarmelo al pueblo y descomprimir un par de zips con multitud de archivos. Fue desesperante. Explorador de archivos: Para mi gusto una gran cagada. La nueva organización es bastante mala, han eliminado el botón para volver a la carpeta anterior, la barra de direcciones no me gusta nada,... Programas que no funcionan: Con Eclipse tuve multitud de problemas para que funcionara y después de buscar en internet tuve que activar una opción para forzar la ejecución como administrador (con el consiguiente cartelito de confirmación). Con algún otro programa no tuve tanta suerte y sencillamente no funcionó. Aero: Ya mostré un video comparativo de Aero y CompizFusion hace unos meses. Sin comentarios.
Sé que se me va a tildar de fanboy de Linux, pero sinceramente, si tengo que aprender a manejar una nueva interfaz, buscar nuevos programas porque los antiguos no funcionan, desaprovechar completamente mi hardware y tener que renovarlo porque el sistema operativo consume muchísimo,... me paso a Linux y aprendo algo que me va a servir en el futuro y me va a dar mayor rendimiento. ¡Anda!, si ya me pasé a Linux hace más de año y medio y vivo tan feliz... :-P.
Resulta que el portatil de mi padre dijo basta y me encargó la tarea de buscarle uno nuevo que no fuera muy caro y que no tuviera que actualizar en mucho tiempo. Después de mucho buscar encontré una oferta muy buena (más de 500EUR de ahorro) por un Dell XPS 1530 con unas características muy completas. La única pega, como no, el sistema operativo: Windows Vista. Mi padre me dejó el portatil durante una semana para probarlo y darle caña a ver qué tal se comportaba y en cuanto a hardware la verdad es que me ha encantado. Pero eso sí, en menos de una semana he terminado asqueado de windows vista. A continuación voy a poner mis impresiones sobre el sistema operativo:
Sé que se me va a tildar de fanboy de Linux, pero sinceramente, si tengo que aprender a manejar una nueva interfaz, buscar nuevos programas porque los antiguos no funcionan, desaprovechar completamente mi hardware y tener que renovarlo porque el sistema operativo consume muchísimo,... me paso a Linux y aprendo algo que me va a servir en el futuro y me va a dar mayor rendimiento. ¡Anda!, si ya me pasé a Linux hace más de año y medio y vivo tan feliz... :-P.
martes, 12 de agosto de 2008
Usando una PocketPC en Linux (III): Sincronización de archivos y conversión de documentos
Después de haber visto cómo configurar, conectar y gestionar los archivos de la PocketPC desde Linux, el siguiente paso es sincronizar nuestros documentos y archivos más importantes. En este apartado tenemos que distinguir entre dos tipos de archivos: los que requieren conversión y los que no. En el primer grupo se encuentran los archivos en formato PocketExcel y PocketWord y en el segundo tenemos fotos, música, archivos de texto, la base de datos de KeePass... La conversión de los archivos es muy importante porque lo que hace ActiveSync en windows cuando copiamos por ejemplo un archivo Excel a la PocketPC es convertirlo automáticamente a formato PocketExcel. Luego, si realizamos la copia a la inversa, ActiveSync lo convierte nuevamente de formato PocketExcel a Excel. Obviamente con esta conversión se pierde información compleja del archivo Excel como por ejemplo las macros, pero en mi caso no es problema porque las excel que utilizo en la PocketPC no suelen ser muy complejas. Por contra, al convertir los archivos a formato PocketExcel ganamos en velocidad de ejecución y tamaño.
Aunque acabamos de comentar que ActiveSync realiza la conversión entre formatos al transferir los archivos, si copiamos un archivo Excel directamente a la SD (por ejemplo), lo podremos abrir sin mayor problema en la PocketPC (siempre teniendo claras sus limitaciones). Esta característica es la que vamos a utilizar para la conversión de archivos.
En los repositorios de Ubuntu se encuentra disponible la utilidad unoconv que nos ayudará en nuestra tarea. Tal y como podemos leer en la ayuda, unoconv es una utilidad en línea de comandos (esto es lo realmente bueno) que nos permite realizar conversiones entre documentos soportados por OpenOffice. Necesita una instancia de OpenOffice para realizar la conversión, por lo que si no tenemos una en ejecución puede arrancar la suya propia de manera temporal.
El uso es muy sencillo, arrancamos la instancia temporal de OpenOffice y realizamos la conversión entre los documentos.
Con este ejemplo se ve que es muy sencillo realizar un pequeño script que convierta nuestros archivos Excel a ODS y viceversa cada vez que queramos sincronizar la PocketPC. Esta misma conversión se podría hacer directamente entre los formatos PocketExcel y ODS, pero por alguna razón la conversión con unoconv falla. Sin embargo si ese mismo archivo PocketExcel lo intento abrir desde OpenOffice, funciona correctamente. Es por esto que la conversión la realizo entre Excel y ODS.
Teniendo todo lo anterior en mente vamos a plantear el siguiente escenario para realizar la conversión.
En el PC trabajaremos con ODS/ODT y en la PocketPC con XLS/DOC. En el PC tendremos los archivos a sincronizar en formato XLS/DOC para realizar la sincronización con la PocketPC. Así, aunque trabajemos en ODS/ODT tendremos que tener en otra carpeta los archivos que queramos sincronizar en formato XLS/DOC. Para realizar la sincronización utilizaremos rsync puesto que podemos montar el filesystem completo de la PocketPC en el directorio que queramos tal y como vimos en el artículo anterior Usando una PocketPC en Linux (II): Gestión de archivos y programas. Para la sincronización vamos a utilizar las opciones delete y update de rsync. Con delete lo que conseguiremos es que si borramos un archivo en el origen, éste se borre también en el destino. Con update no se sobreescriben archivos en el destino si la fecha es posterior a la del origen. La sincronización se realiza en dos pasos, primero desde el ordenador a la PocketPC y posteriormente desde la PocketPC al ordenador.
Aunque la idea es buena este script tiene algunas limitaciones:
Aunque sólo se transfieran unos cuantos archivos entre la PocketPC y el ordenador, siempre se realiza la conversión de todos ellos. Habría que parsear el log de rsync para procesar posteriormente con unoconv sólo los archivos modificados. Debido a lo anterior, la fecha de modificación de los archivos también cambia con cada sincronización. Por propias limitaciones de unoconv, y según podemos leer en la ayuda, necesitamos una sesión X para arrancar la instancia de OpenOffice que realiza la conversión:
Aún con las limitaciones comentadas anteriormente tenéis un esqueleto funcional para poder mejorarlo y hacer la versión 0.2 de script con las mejoras que he propuesto. Si alguien se anima a mejorarlo que me lo pase y actualizaré el artículo.
Para finalizar añadir que también vamos a utilizar rsync para la sincronización de la base de datos de KeePass, así conseguimos tener siempre sincronizados los cambios que hagamos tanto en el ordenador como en la PocketPC. Recordamos que realizamos la sincronización en los dos sentidos para asegurarnos de tener la siempre la información más actual en todos los dispositivos.
Con este pequeño script hemos logrado sincronizar nuestro archivo de passwords entre la PocketPC y Linux, además se podrían añadir otros tipos de archivos y otras rutas para adaptarlo a nuestras necesidades. Como siempre, estoy abierto a cualquier sugerencia para mejorarlo.
Aunque acabamos de comentar que ActiveSync realiza la conversión entre formatos al transferir los archivos, si copiamos un archivo Excel directamente a la SD (por ejemplo), lo podremos abrir sin mayor problema en la PocketPC (siempre teniendo claras sus limitaciones). Esta característica es la que vamos a utilizar para la conversión de archivos.
En los repositorios de Ubuntu se encuentra disponible la utilidad unoconv que nos ayudará en nuestra tarea. Tal y como podemos leer en la ayuda, unoconv es una utilidad en línea de comandos (esto es lo realmente bueno) que nos permite realizar conversiones entre documentos soportados por OpenOffice. Necesita una instancia de OpenOffice para realizar la conversión, por lo que si no tenemos una en ejecución puede arrancar la suya propia de manera temporal.
unoconv is a command line utility that can convert any file format that OpenOffice can
import, to any file format that OpenOffice is capable of exporting.
unoconv uses the OpenOffice's UNO bindings for non-interactive conversion of documents
and therefor needs an OpenOffice instance to communicate with. Therefore if it cannot
find one, it will start its own instance for temporary usage. If desired, one can
start a "listener" instance to use for subsequent connections or even for remote
connections.
El uso es muy sencillo, arrancamos la instancia temporal de OpenOffice y realizamos la conversión entre los documentos.
ivan@doraemon:~$ unoconv --listener &Con esto hemos convertido a formato excel y word respectivamente los archivos HojaCalculo.ods y Documento.odt.
ivan@doraemon:~$ unoconv -f xls HojaCalculo.ods
ivan@doraemon:~$ unoconv -f doc Documento.odt
ivan@doraemon:~$ kill -15 %-
Con este ejemplo se ve que es muy sencillo realizar un pequeño script que convierta nuestros archivos Excel a ODS y viceversa cada vez que queramos sincronizar la PocketPC. Esta misma conversión se podría hacer directamente entre los formatos PocketExcel y ODS, pero por alguna razón la conversión con unoconv falla. Sin embargo si ese mismo archivo PocketExcel lo intento abrir desde OpenOffice, funciona correctamente. Es por esto que la conversión la realizo entre Excel y ODS.
Teniendo todo lo anterior en mente vamos a plantear el siguiente escenario para realizar la conversión.
#!/bin/sh
#
# syncPocketPC.sh: Script para la sincronización de la PocketPC
# y linux por medio de rsync
#
# Iván López Martín
# http://lopezivan.blogspot.com
#
SYNC_DIR=/home/ivan/MisDocs/PocketPC/
TMP_SYNC_DIR=/home/ivan/MisDocs/PocketPC/tmp/
POCKETPC_DIR=/home/ivan/PocketPC/SD\ Card/Personal/
# Sincronización desde el PC a la PocketPC
####
cd $TMP_SYNC_DIR
unoconv --listener &
unoconv -f xls $SYNC_DIR/*.ods
unoconv -f doc $SYNC_DIR/*.odt
mv $SYNC_DIR/*.xls $TMP_SYNC_DIR
mv $SYNC_DIR/*.doc $TMP_SYNC_DIR
kill -15 %-
rsync -avz --delete --update ${TMP_SYNC_DIR} "${POCKETPC_DIR}"
# Sincronización desde la PocketPC al PC
####
rsync -avz --delete --update "${POCKETPC_DIR}" ${TMP_SYNC_DIR}
cd $SYNC_DIR
unoconv --listener &
unoconv -f ods $TMP_SYNC_DIR/*.xls
unoconv -f odt $TMP_SYNC_DIR/*.doc
mv $TMP_SYNC_DIR/*.xls $SYNC_DIR
mv $TMP_SYNC_DIR/*.doc $SYNC_DIR
kill -15 %-
Aunque la idea es buena este script tiene algunas limitaciones:
unoconv uses the UNO bindings to connect to OpenOffice, in absence of a usable socket, it will start its own OpenOffice instance with the correct parameters. However, OpenOffice requires a working DISPLAY (even with -headless option) and therefor you cannot run it in a true console, you need X.
Aún con las limitaciones comentadas anteriormente tenéis un esqueleto funcional para poder mejorarlo y hacer la versión 0.2 de script con las mejoras que he propuesto. Si alguien se anima a mejorarlo que me lo pase y actualizaré el artículo.
Para finalizar añadir que también vamos a utilizar rsync para la sincronización de la base de datos de KeePass, así conseguimos tener siempre sincronizados los cambios que hagamos tanto en el ordenador como en la PocketPC. Recordamos que realizamos la sincronización en los dos sentidos para asegurarnos de tener la siempre la información más actual en todos los dispositivos.
#!/bin/sh
#
# syncKeePass.sh: Script para la sincronización de la base de datos
# de KeePass entre la PocketPC y linux por medio de rsync
#
# Iván López Martín
# http://lopezivan.blogspot.com
#
LINUX_DIR=/home/ivan/MisDocs/
POCKETPC_DIR=/home/ivan/PocketPC/SD\ Card/Personal/
# Linux -> PocketPC
rsync -avz --update --include=*.kdb --exclude=* "${LINUX_DIR}" "${POCKETPC_DIR}"
# PocketPC -> Linux
rsync -avz --update --include=*.kdb --exclude=* "${POCKETPC_DIR}" "${LINUX_DIR}"
Con este pequeño script hemos logrado sincronizar nuestro archivo de passwords entre la PocketPC y Linux, además se podrían añadir otros tipos de archivos y otras rutas para adaptarlo a nuestras necesidades. Como siempre, estoy abierto a cualquier sugerencia para mejorarlo.
lunes, 4 de agosto de 2008
Usando una PocketPC en Linux (II): Gestión de archivos y programas
Como continuación de la entrada anterior Usando una PocketPC en Linux (I): Conexión y configuración, en ésta vamos a ver cómo utilizar la PocketPC una vez que ya se habla con Linux. Más concretamente nos centraremos en la instalación de software y en la gestión de los archivos.
Hay tres paquetes imprescindibles que nos ayudarán en esta tarea: synce-gnomevfs, synce-trayicon y synce-software-manager. Todos se pueden descargar desde Sourceforge.net. La versión que yo tengo instalada es la 0.9 puesto que la compilación de la última 0.12 me ha resultado imposible. He resuelto multitud de dependencias y he compilado algunas librerías y paquetes, pero finalmente no he sido capaz de compilar todo. Me temo que tendré que esperar a que saquen los binarios de la nueva versión o a intentarlo de nuevo en el futuro. Lo que he hecho es descargarme los paquetes de la versión 0.9 en formato rpm y convertirlos a .deb con alien para instalarlos de la manera habitual con dpkg.
synce-gnomevfs: Con este plugin podremos acceder al sistema de ficheros de la PocketPC desde Nautilus escribiendo simplemente synce:///. El problema es que al parecer sólo funciona hasta la versión 7.10 de Ubuntu. En su momento lo utilicé y la integración entre Nautilus y la PocketPC era muy buena. synce-trayicon: Es un icono en el la barra de notificaciones que nos permite acceder a la PocketPC y conectarla y desconectarla. synce-software-manager: Para instalar y desinstalar aplicaciones de forma gráfica de manera similar a como haríamos con windows. Por ejemplo, aquí muestro la instalación de la última versión de KeePass.
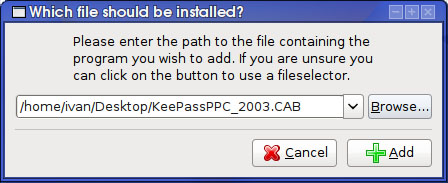
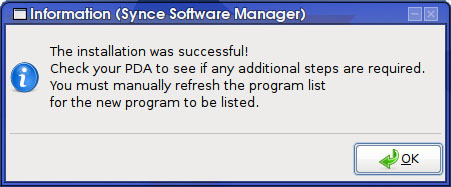
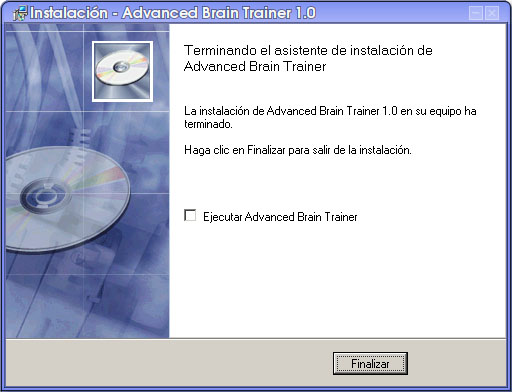
El software de PocketPC en ocasiones no viene como un simple archivo .cab, sino que es un instalador .exe en el que viene empaquetado el archivo .cab correspondiente. Al ejecutar este instalador lo que ocurre es que se desempaqueta el .exe y por medio de ActiveSync se instala el .cab en la PocketPC. En el caso de encontrarnos con una aplicación en este formato, es un poco cuestión de suerte que la podamos instalar o no desde linux. Algunas se desempaquetarán correctamente (ejecutándose desde wine) y podremos instalar el .cab siguiendo el método anterior. Otras aplicaciones, sin embargo, no detectarán ActiveSync instalado y abortarán la instalación. Por ejemplo, la instalación de una demo del Advanced Brain Trainer se ha instalado sin problemas.
Pero con alguna otra aplicación que he probado no ha funcionado correctamente por la ausencia de ActiveSync. En ese caso, creo que no queda otro remedio que acudir a windows (aunque eso sí, virtualizado) para instalar la aplicación.
A parte de instalar software, lo más importante es navegar por las carpetas de la PocketPC y poder transferir archivos de una manera rápida y cómoda. Así, como alternativa a no poder utilizar Synce-gnomevfs he encontrado SynceFS que sí está disponible en formato .deb (también en Sourceforge.net) y que a mi entender es todavía mejor porque ofrece muchas más posibilidades como ya veremos en el siguiente artículo. Con esta utilidad podemos montar el filesystem completo de la PocketPC en cualquier directorio que queramos y podremos acceder a él y manipular los archivos directamente sin los comando synce-pls, synce-mkdir,...
Como véis, es mucho más amigable usar ls que synce-pls y tratar la PocketPC como si fuera un directorio más en nuestro sistema.
Hay tres paquetes imprescindibles que nos ayudarán en esta tarea: synce-gnomevfs, synce-trayicon y synce-software-manager. Todos se pueden descargar desde Sourceforge.net. La versión que yo tengo instalada es la 0.9 puesto que la compilación de la última 0.12 me ha resultado imposible. He resuelto multitud de dependencias y he compilado algunas librerías y paquetes, pero finalmente no he sido capaz de compilar todo. Me temo que tendré que esperar a que saquen los binarios de la nueva versión o a intentarlo de nuevo en el futuro. Lo que he hecho es descargarme los paquetes de la versión 0.9 en formato rpm y convertirlos a .deb con alien para instalarlos de la manera habitual con dpkg.
 |
 |
El software de PocketPC en ocasiones no viene como un simple archivo .cab, sino que es un instalador .exe en el que viene empaquetado el archivo .cab correspondiente. Al ejecutar este instalador lo que ocurre es que se desempaqueta el .exe y por medio de ActiveSync se instala el .cab en la PocketPC. En el caso de encontrarnos con una aplicación en este formato, es un poco cuestión de suerte que la podamos instalar o no desde linux. Algunas se desempaquetarán correctamente (ejecutándose desde wine) y podremos instalar el .cab siguiendo el método anterior. Otras aplicaciones, sin embargo, no detectarán ActiveSync instalado y abortarán la instalación. Por ejemplo, la instalación de una demo del Advanced Brain Trainer se ha instalado sin problemas.
 |
 |
Pero con alguna otra aplicación que he probado no ha funcionado correctamente por la ausencia de ActiveSync. En ese caso, creo que no queda otro remedio que acudir a windows (aunque eso sí, virtualizado) para instalar la aplicación.
A parte de instalar software, lo más importante es navegar por las carpetas de la PocketPC y poder transferir archivos de una manera rápida y cómoda. Así, como alternativa a no poder utilizar Synce-gnomevfs he encontrado SynceFS que sí está disponible en formato .deb (también en Sourceforge.net) y que a mi entender es todavía mejor porque ofrece muchas más posibilidades como ya veremos en el siguiente artículo. Con esta utilidad podemos montar el filesystem completo de la PocketPC en cualquier directorio que queramos y podremos acceder a él y manipular los archivos directamente sin los comando synce-pls, synce-mkdir,...
ivan@doraemon:~$ sudo apt-get install syncefs
ivan@doraemon:~$ sudo modprobe coda
ivan@doraemon:~$ sudo echo "none /home/ivan/PocketPC cefs rw,user,noauto,codadev=/dev/cfs0 0 0" >> /etc/fstab
ivan@doraemon:~$ mount PocketPC
SynCE FS using "/dev/cfs0" (CODA v3)
ivan@doraemon:~$ ls -l PocketPC
total 1541
drwxrwxr-x 1 ivan ivan 0 2004-01-01 02:04 Application Data
drwxrwxr-x 1 ivan ivan 0 2004-01-01 02:59 Archivos de programa
drwxrwxr-x 1 ivan ivan 0 2004-01-01 11:00 ConnMgr
drwxrwxr-x 1 ivan ivan 0 1998-01-01 13:00 iPAQ File Store
drwxrwxr-x 1 ivan ivan 0 2004-01-01 02:05 itn
drwxrwxr-x 1 ivan ivan 0 2004-01-01 02:59 My Documents
drwxrwxr-x 1 ivan ivan 0 2004-01-01 02:59 profiles
drwxrwxr-x 1 ivan ivan 0 2004-01-01 02:59 Program Files
drwxrwxr-x 1 ivan ivan 0 1998-01-01 13:00 SD Card
-rw-rw-r-- 1 ivan ivan 49152 2007-02-04 10:08 SystemHeap
drwxrwxr-x 1 ivan ivan 0 2004-01-01 02:59 Temp
-rw-rw-r-- 1 ivan ivan 480400 2005-12-26 20:20 templ.voc
drwxrwxr-x 1 ivan ivan 0 2006-12-30 17:48 TomTom
drwxrwxr-x 1 ivan ivan 0 2004-01-01 02:59 Windows
ivan@doraemon:~$ synce-pls ../ | sort -r
--D------T 1998-01-01 13:00:00 SD Card/
--D------T 1998-01-01 13:00:00 iPAQ File Store/
Directory 2006-12-30 17:48:10 TomTom/
Directory 2004-01-01 11:00:08 ConnMgr/
Directory 2004-01-01 02:59:52 Program Files/
Directory 2004-01-01 02:59:52 profiles/
Directory 2004-01-01 02:59:51 My Documents/
Directory 2004-01-01 02:59:51 Archivos de programa/
Directory 2004-01-01 02:59:50 Windows/
Directory 2004-01-01 02:59:50 Temp/
Directory 2004-01-01 02:05:19 itn/
Directory 2004-01-01 02:04:17 Application Data/
Archive 49152 2007-02-04 10:08:19 SystemHeap
AC-------- 480400 2005-12-26 20:20:33 templ.voc
Como véis, es mucho más amigable usar ls que synce-pls y tratar la PocketPC como si fuera un directorio más en nuestro sistema.
jueves, 24 de julio de 2008
Usando una PocketPC en Linux (I): Conexión y configuración
Una vez que decides cambiar de windows a linux haces una lista con los programas que utilizas para buscar sustitutos en linux y poder seguir trabajando como antes. Poco a poco vas adaptándote a esos nuevos programas y por fin te queda muy poco por migrar. Algo que he ido dejando ha sido la sincronización entre mi PocketPC y Linux.
Lo primero que tenemos que hacer es conectar la PocketPC a la docking y ver si linux la reconoce sin problemas.
Ahora instalamos los paquetes necesarios para la comunicación con la PocketPC.
Durante la instalación de Synce tendremos que configurarlo. Con las opciones que aparecen por defecto es más que suficiente. El DNS sólo lo rellenaremos en caso de que queramos navegar desde la PocketPC.
Configuramos Synce y le indicamos dónde está la PocketPC:
Ejecutamos dccm que es el demonio encargado de gestionar la conexión con la PocketPC:
Por fin, iniciamos la conexión con la PocketPC:
Y listo, si todo ha ido bien ya tendremos nuestra PocketPC conectada a Linux. Puede que todavía en la PocketPC no se haya detectado la conexión, en este caso lo único que tenemos que hacer es ejecutar a mano ActiveSync.
Una vez conectada, vamos a probarlo y a ver cómo gestionarla:
Por ejemplo podemos hacer un ping a la IP que configuramos al instalar Synce:
También podemos, por ejemplo, ejecutar synce-pstatus para ver la información de nuestra PocketPC como la versión del sistema operativo, la batería restante,...:
Hay más comandos con los que poder juguetear e interactuar con nuestra PocketPC, siendo la mayoría similares a los equivalentes desde línea de comandos: ls, mv, rm, mkdir,...: synce-pls, synce-pmv, synce-prm,...
También podemos configurar la sincronización con Evolution tanto de los contactos, las tareas o las citas. Para ello es necesario instalar adicionalmente el paquete synce-multisync-plugin. Aunque he estado probando la sincronización de las citas, tareas y contactos, no es algo a lo que le de mucha importancia porque ni siquiera lo hacía en windows, así que en linux tampoco lo voy a usar. Sólo quiero comentar que al menos en mi caso la sincronización me lió una buena puesto que me duplicó contactos y citas en la PocketPC y luego los tuve que ir borrando a mano. En fín, un aspecto a mejorar...
Seguimos. Cada vez que conectemos nuestra PocketPC tenemos que ejecutar tanto dccm como synce-serial-start, éste último como root. Para solucionar este pequeño problema podemos hacer uso de las reglas udev. Tenéis un excelente artículo en el blog de Vicente Navarro.
Creamos la regla y la cargamos:
Luego, si trabajamos por ejemplo con Ubuntu, desde el menú System->Preferences->Sessions añadimos que dccm (/usr/bin/dccm) se ejecute al comienzo de la sesión y listo. Ahora cada vez que conectemos la PocketPC se conectará automáticamente al ordenador.
ivan@doraemon:~$ dmesg
[784.372804] usb 1-2: new full speed USB device using uhci_hcd and address 5
[784.539787] usb 1-2: configuration #1 chosen from 1 choice
[784.542744] ipaq 1-2:1.0: PocketPC PDA converter detected
[784.544972] usb 1-2: PocketPC PDA converter now attached to ttyUSB0
ivan@doraemon:~$ sudo apt-get install synce-serial synce-dccm librra0 librra0-tools librapi2-tools
Puerto: /dev/ttyUSB0
IPs: 192.168.131.102 y 192.168.131.201
DNS:
ivan@doraemon:~$ sudo synce-serial-config ttyUSB0
You can now run synce-serial-start to start a serial connection.
ivan@doraemon:~$ dccm
ivan@doraemon:~$ sudo synce-serial-start
synce-serial-start is now waiting for your device to connect
Y listo, si todo ha ido bien ya tendremos nuestra PocketPC conectada a Linux. Puede que todavía en la PocketPC no se haya detectado la conexión, en este caso lo único que tenemos que hacer es ejecutar a mano ActiveSync.
Una vez conectada, vamos a probarlo y a ver cómo gestionarla:
ivan@doraemon:~$ ping -c 2 192.168.131.201
PING 192.168.131.201 (192.168.131.201) 56(84) bytes of data.
64 bytes from 192.168.131.201: icmp_seq=1 ttl=128 time=2.94 ms
64 bytes from 192.168.131.201: icmp_seq=2 ttl=128 time=2.79 ms
--- 192.168.131.201 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1003ms
rtt min/avg/max/mdev = 2.799/2.873/2.948/0.091 ms
ivan@doraemon:~$ synce-pstatus
Version
=======
Version: 4.21.1088 (Microsoft Windows Mobile 2003 Pocket PC Phone Edition)
Platform: 3 (Windows CE)
Details: ""
System
======
Processor architecture: 5 (ARM)
Processor type: 2577 (StrongARM)
Page size: 0x10000
Power
=====
ACLineStatus: 00 (Offline)
Status for main battery
=========================
Flag: 1 (High)
LifePercent: 55%
LifeTime: 32895
FullLifeTime: 7048
Status for backup battery
=========================
Flag: 1 (High)
LifePercent: 100%
LifeTime: Unknown
FullLifeTime: Unknown
Store
=====
Store size: 69423104 bytes (66 megabytes)
Free space: 35657576 bytes (34 megabytes)
Memory for storage: 69611520 bytes (66 megabytes)
Memory for RAM: 59920384 bytes (57 megabytes)
Hay más comandos con los que poder juguetear e interactuar con nuestra PocketPC, siendo la mayoría similares a los equivalentes desde línea de comandos: ls, mv, rm, mkdir,...: synce-pls, synce-pmv, synce-prm,...
También podemos configurar la sincronización con Evolution tanto de los contactos, las tareas o las citas. Para ello es necesario instalar adicionalmente el paquete synce-multisync-plugin. Aunque he estado probando la sincronización de las citas, tareas y contactos, no es algo a lo que le de mucha importancia porque ni siquiera lo hacía en windows, así que en linux tampoco lo voy a usar. Sólo quiero comentar que al menos en mi caso la sincronización me lió una buena puesto que me duplicó contactos y citas en la PocketPC y luego los tuve que ir borrando a mano. En fín, un aspecto a mejorar...
Seguimos. Cada vez que conectemos nuestra PocketPC tenemos que ejecutar tanto dccm como synce-serial-start, éste último como root. Para solucionar este pequeño problema podemos hacer uso de las reglas udev. Tenéis un excelente artículo en el blog de Vicente Navarro.
Creamos la regla y la cargamos:
ivan@doraemon:~$ sudo vi /etc/udev/rules.d/60-ipaq.rules
BUS!="usb", ACTION!="add", KERNEL!="ttyUSB*", GOTO="synce_rules_end"
RUN+="/usr/bin/synce-serial-start"
LABEL="synce_rules_end"
ivan@doraemon:~$ sudo /etc/init.d/udev reload
* Reloading kernel event manager... [ OK ]
Luego, si trabajamos por ejemplo con Ubuntu, desde el menú System->Preferences->Sessions añadimos que dccm (/usr/bin/dccm) se ejecute al comienzo de la sesión y listo. Ahora cada vez que conectemos la PocketPC se conectará automáticamente al ordenador.
sábado, 12 de julio de 2008
Cómo gestionar nuestras contraseñas
En los tiempos que corren todo el mundo gestiona gran cantidad de contraseñas: el pin del móvil, la contraseña del pc del trabajo, de casa, cuentas de correo, del banco, foros, webs,... En total debemos recordar una gran cantidad de usuarios y contraseñas diferentes en nuestro día a día. En los servicios que utilizamos con más frecuencia no hay problema, pero ¿qué ocurre con esas webs en las que entramos muy de vez en cuando?. En la mayoría de los casos optamos por la solución más radical: la misma contraseña para todos los sitios o como mucho dos o tres que prácticamente son la misma con pequeñas variaciones.
Existen gran cantidad de programas para ayudarnos a gestionar las contraseñas pero yo me quedo con KeePass. Los motivos: además de ser open source también es multiplataforma. Estos dos motivos, tratandose de un software en el que vamos a depositar toda nuestra información privada, creo que son suficientemente importantes para que nos decidamos a utilizar esta herramienta frente a otras. El código fuente está disponible y cualquiera que lo desee lo puede auditar para comprobar que no hay puertas traseras y ni fallos en la implementación. Tratándose de información tan sensible, a mi esta herramienta me inspira gran confianza.
Antes lo utilizaba en windows y ahora lo utilizo en linux (KeePassX) y también en la PocketPc (KeePassPPC).
Con este programa sólo es necesario recordar una contraseña, la que se utiliza para cifrar el archivo en el que se almacenan todas nuestras contraseñas. La interfaz es muy intuitiva y sencilla de utilizar y permite agrupar las contraseñas por grupos, añadir información adicional, generar contraseñas aleatorias si no queremos pensar ninguna, definir fechas de expiración que nos recuerden que debemos cambiar la contraseña,... De hecho, una vez generadas las contraseñas, ni siquiera tenemos que visualizarlas y copiarlas en la web a la que queremos acceder. Haciendo doble-click en el password, éste se nos copia al portapapeles para que podamos pegarlo en la web y a los 10 segundos se borra automáticamente para evitar que pueda caer en manos peligrosas.
Os pongo un par de pantallazos de la interfaz Linux y PocketPc. Como podéis ver son muy parecidas y hacen su trabajo a la perfección.
Además, a esto le añadimos que también existe una versión portable que siempre llevo en un pendrive conmigo, ya no tenemos excusa para poder tener passwords realmente complicados y todos distintos para cada servicio de internet. Lo único de lo que debemos preocuparnos es de tener sincronizados el archivo de la base de datos entre el ordenador, la PocketPc y el pendrive para estar siempre con la información al día. Pero eso ya lo veremos en otro post...
Existen gran cantidad de programas para ayudarnos a gestionar las contraseñas pero yo me quedo con KeePass. Los motivos: además de ser open source también es multiplataforma. Estos dos motivos, tratandose de un software en el que vamos a depositar toda nuestra información privada, creo que son suficientemente importantes para que nos decidamos a utilizar esta herramienta frente a otras. El código fuente está disponible y cualquiera que lo desee lo puede auditar para comprobar que no hay puertas traseras y ni fallos en la implementación. Tratándose de información tan sensible, a mi esta herramienta me inspira gran confianza.
Antes lo utilizaba en windows y ahora lo utilizo en linux (KeePassX) y también en la PocketPc (KeePassPPC).
Con este programa sólo es necesario recordar una contraseña, la que se utiliza para cifrar el archivo en el que se almacenan todas nuestras contraseñas. La interfaz es muy intuitiva y sencilla de utilizar y permite agrupar las contraseñas por grupos, añadir información adicional, generar contraseñas aleatorias si no queremos pensar ninguna, definir fechas de expiración que nos recuerden que debemos cambiar la contraseña,... De hecho, una vez generadas las contraseñas, ni siquiera tenemos que visualizarlas y copiarlas en la web a la que queremos acceder. Haciendo doble-click en el password, éste se nos copia al portapapeles para que podamos pegarlo en la web y a los 10 segundos se borra automáticamente para evitar que pueda caer en manos peligrosas.
Os pongo un par de pantallazos de la interfaz Linux y PocketPc. Como podéis ver son muy parecidas y hacen su trabajo a la perfección.
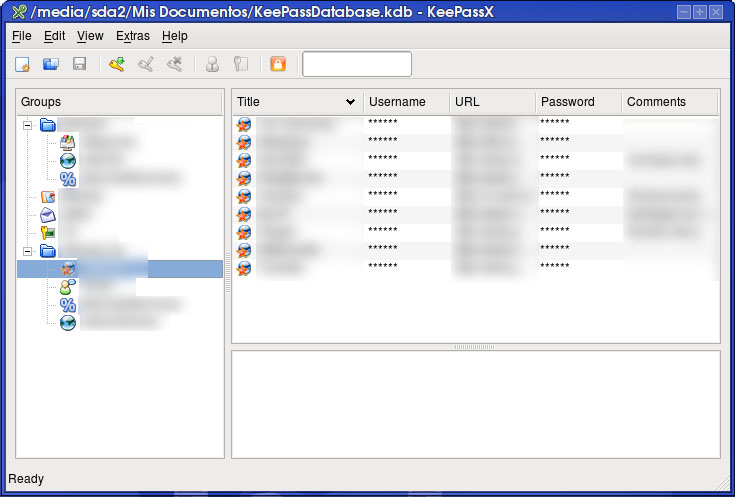 | 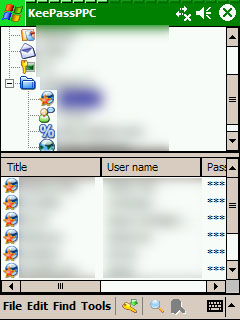 |
| Interfaz Linux | Interfaz PocketPc |
Además, a esto le añadimos que también existe una versión portable que siempre llevo en un pendrive conmigo, ya no tenemos excusa para poder tener passwords realmente complicados y todos distintos para cada servicio de internet. Lo único de lo que debemos preocuparnos es de tener sincronizados el archivo de la base de datos entre el ordenador, la PocketPc y el pendrive para estar siempre con la información al día. Pero eso ya lo veremos en otro post...
jueves, 26 de junio de 2008
Exceso de información
Últimamente me doy cuenta de que no tengo apenas tiempo libre. Me gustaría escribir más en el blog y hacer otras muchas cosas, pero cada vez que me pongo con el ordenador siempre termino haciendo lo mismo: leer, leer y leer. Cada mañana cuando abro el Google Reader me encuentro con cientos de artículos sin leer. Da igual que a lo largo del día o por la tarde-noche los deje prácticamente a cero, vuelven a aparecer. Lo normal es que haya unos 200-300 de los que tengo como favoritos y leo sin falta. Luego, si algún día tengo más tiempo voy leyendo otros, pero estos sólo si puedo. Parándome a pensarlo más fríamente me estoy dando cuenta de que esto no es vida. Si en algún momento me paso 3 ó 4 días sin poder leer, luego tengo una barbaridad de temas pendientes y no me pongo al día. Al final me estreso y termino marcando la mayoría como leídos y seguro que me pierdo información interesante. Actualmente tengo 166 blogs/webs marcados como favoritos y estos son, como he comentado, los que más suelo leer. Luego tengo unos 20 que leo cuando tengo un ratito y muchísimos más que ya hace bastante tiempo que no leo. Me he dado cuenta que tanto exceso de información no es sano, así que me he propuesto cambiar esto para poder dedicarle más tiempo a lo que me interesa (incluído el blog).
Obviamente todos esos blogs que tengo en favoritos no tienen el mismo ritmo de publicación. Hay algunos que publican una vez por semana y otros 20 veces en un día, por lo que no se pueden tratar igual. Lo que voy a hacer es lo siguiente:
Ordenar los blogs por prioridad de tal forma que siempre empezaré a leer por el principio. Así, si tengo poco tiempo sé que leeré los que más me interesan. Eliminar todos los blogs que no leo nunca. No me aportan nada y así no tengo el Google Reader con información que no me sirve. Reducir la lista de los blogs favoritos. Esos 166+20 son demasiados y me han llevado a esta situación. Una vez que tenga la lista ordenada voy a ir eliminando los que no me aporten mucho. Mi objetivo es tener apróximadamente 100 favoritos e incluso menos. No añadir ningún blog nuevo si previamente no quito dos. Así, si realmente pienso que un blog me puede aportar algo nuevo voy a tener que quitar dos. Si no logro elegir esos dos, significa que ese nuevo blog no me interesa tanto.
De esta forma voy a conseguir más tiempo libre para otras muchas cosas que tengo pendientes y a las que actualmente no puedo dedicarles prácticamente tiempo. Tengo un par de artículos pendientes para el blog de los que sólo me queda un pequeño empujón para terminarlos. Además ahora voy a comenzar junto con mi amigo Jose un proyecto en Java, Hibernate, MySql,... utilizando el API de Google y algo más que irá surgiendo. El proyecto ya lo ha empezado él y me estoy poniendo al día. Ya éstá la primera versión alfa en el SVN de Google Code aunque todavía no os daré la url. Prometo un post contando el proyecto.
Y bueno para finalizar os lanzo un par de preguntas. ¿Leéis muchas fuentes de información y pensáis que no dais abasto?, ¿qué criterio seguís para leerlas, como ordenáis,...?, ¿qué haríais vosotros para organizaros?. A ver si entre todos me dais alguna idea más.
Obviamente todos esos blogs que tengo en favoritos no tienen el mismo ritmo de publicación. Hay algunos que publican una vez por semana y otros 20 veces en un día, por lo que no se pueden tratar igual. Lo que voy a hacer es lo siguiente:
De esta forma voy a conseguir más tiempo libre para otras muchas cosas que tengo pendientes y a las que actualmente no puedo dedicarles prácticamente tiempo. Tengo un par de artículos pendientes para el blog de los que sólo me queda un pequeño empujón para terminarlos. Además ahora voy a comenzar junto con mi amigo Jose un proyecto en Java, Hibernate, MySql,... utilizando el API de Google y algo más que irá surgiendo. El proyecto ya lo ha empezado él y me estoy poniendo al día. Ya éstá la primera versión alfa en el SVN de Google Code aunque todavía no os daré la url. Prometo un post contando el proyecto.
Y bueno para finalizar os lanzo un par de preguntas. ¿Leéis muchas fuentes de información y pensáis que no dais abasto?, ¿qué criterio seguís para leerlas, como ordenáis,...?, ¿qué haríais vosotros para organizaros?. A ver si entre todos me dais alguna idea más.
martes, 24 de junio de 2008
Dos meses con WiiFit
Hace ya dos meses que compramos el WiiFii. Ese revolucionario juego de Nintendo para la Wii que prometía ponernos en forma o al menos hacer que nuestra vida no fuera tan sedentaria. Después de este tiempo jugando/entrenando debo decir que el juego es muy bueno. Todo comienza con la elección del Mii que te va a representar además de tu edad y altura. Después de pesarte aparece en pantalla tu Índice de Masa Corporal y tu Mii va engordando según tu peso. Luego, en función de un par de pruebas de equilibrio básico calcula tu edad WiiFit.
Las pruebas están divididas en cuatro categorías distintas: Yoga, Tonificación, Aerobic y Equilibrio. Como seguro que habéis visto numerosos videos y leído un montón de comentarios del WiiFit tampoco os quiero aburrir más, sino dar mi impresión desde el punto de vista del jugador.
El juego es muy bueno y la Wii Balance Board, que así es como se llama la tabla, es extremadamente precisa. Algunos ejercicios de yoga pueden parecer una tontería con eso de poner posturitas, pero si los haces en serio cansan. Luego, los de tonificación son más en plan gimnasio, haces flexiones, torsiones, estiramientos,... Los más entretenidos para jugar en grupo son los de equilibrio. En esta categoría se encuentran el slalom, el salto de ski, el de cabecear balones de futbol,... muy divertidos. Finalmente, los de Aerobic son para sudar: haces step, carrera, boxeo rítmico,...
Después de este tiempo la verdad es que el juego sigue enganchando y no te cansas de él a las primeras de cambio, aunque sí es cierto que últimamente juego un poco menos, aunque es por otros motivos. En mi caso, las pruebas que más me gustan son las de tonificación y las de equilibrio.
En definitiva, que si tienes una Wii y quieres esperimentar otra forma de jugar, anímate y hazte con el juego, no te defraudará.
P.D: Para los más morbosos/cotillas diré que mi IMC es de 22, por lo que estoy en el peso ideal. Así mi madre ya no tiene motivos para decirme más eso de te veo muy delgado ;-).
Las pruebas están divididas en cuatro categorías distintas: Yoga, Tonificación, Aerobic y Equilibrio. Como seguro que habéis visto numerosos videos y leído un montón de comentarios del WiiFit tampoco os quiero aburrir más, sino dar mi impresión desde el punto de vista del jugador.
El juego es muy bueno y la Wii Balance Board, que así es como se llama la tabla, es extremadamente precisa. Algunos ejercicios de yoga pueden parecer una tontería con eso de poner posturitas, pero si los haces en serio cansan. Luego, los de tonificación son más en plan gimnasio, haces flexiones, torsiones, estiramientos,... Los más entretenidos para jugar en grupo son los de equilibrio. En esta categoría se encuentran el slalom, el salto de ski, el de cabecear balones de futbol,... muy divertidos. Finalmente, los de Aerobic son para sudar: haces step, carrera, boxeo rítmico,...
Después de este tiempo la verdad es que el juego sigue enganchando y no te cansas de él a las primeras de cambio, aunque sí es cierto que últimamente juego un poco menos, aunque es por otros motivos. En mi caso, las pruebas que más me gustan son las de tonificación y las de equilibrio.
En definitiva, que si tienes una Wii y quieres esperimentar otra forma de jugar, anímate y hazte con el juego, no te defraudará.
P.D: Para los más morbosos/cotillas diré que mi IMC es de 22, por lo que estoy en el peso ideal. Así mi madre ya no tiene motivos para decirme más eso de te veo muy delgado ;-).
jueves, 29 de mayo de 2008
Los anuncios patrocinados y la publicidad en el blog
Se ha hablado este último mes en multitud de sitios sobre los post patrocinados y la imagen que crean en un blog. Además, también se ha tocado el tema de la publicidad y cómo afecta a los usuarios recurrentes de una página. En mi caso he realizado tres análisis patrocinados y el blog tiene publicidad desde julio de 2007.
A mi me gusta escribir el blog, si no me gustara no lo haría, eso está muy claro. Pienso que todos los que tenemos blogs y le dedicamos horas a investigar, preparar artículos, responder las preguntas de los comentarios,... lo hacemos porque nos gusta y nos apetece. Si fuera una obligación o una carga, o no lo haríamos o lo llevaríamos muchísimo peor y al final se notaría en la cantidad y la calidad de los artículos.
Con estas premisas, si además de hacer lo que te gusta y te apetece, puedes sacar algo a cambio, mejor, no?. Este blog tiene una temática definida (aunque empezó siendo un blog personal en el que contaba lo que me pasaba por la cabeza), por lo que no estoy dispuesto a aceptar ningún análisis patrocinado que no pueda aportar algo a los lectores. Me han llegado solicitudes de buscadores de vuelos, webs de poesía, hoteles en diversos puntos de España (en esta última semana más de 40 solicitudes),... y eso es algo por lo que no estoy dispuesto a pasar. Una cosa es sacar algún provecho y otra es venderte a lo que sea. Yo también leo muchos blogs y cuando me encuentro con un análisis patrocinado que no tiene nada que ver con la temática del blog me enfado bastante.
Por otro lado está el tema de la publicidad. Al principio este blog no tenía publicidad. Total, era un blog que no leía nadie y en el que escribía sobre cualquier tema. En este post se pueden observar las estadísticas de los primeros cuatro meses y son de pena. El cuarto mes tuve 221 visitantes únicos: ¡¡en todo un mes!!, cuando ahora la media está en torno a las 250-300 visitas diarias. Luego, en julio del año pasado, hablando con un amigo (Jose), después de salir en portada de barrapunto con el artículo del Raid 1 en linux, éste me dijo que como ya tenía más visitas, pusiera publicidad, que total, poquito a poco iría acumulando algo. Al final le hice caso, pero vamos, que tampoco es nada del otro mundo y no voy a poder dejar el trabajo para vivir del blog... ;-). Además el ritmo de publicación ha disminuido bastante últimamente porque estoy más liado en el curro y tengo menos tiempo libre en casa del que me gustaría. Ahora mismo estoy posteando desde un hotel de Spiez (Suiza) en el que llevo toda la semana por motivos de trabajo y en unas horas seguramente coja un avión de vuelta a España.
En definitiva, que voy a mantener la publicidad porque en algún momento me servirá para algún pequeño caprichito y los análisis patrocinados siempre que puedan os aportar algo a todos vosotros.
A mi me gusta escribir el blog, si no me gustara no lo haría, eso está muy claro. Pienso que todos los que tenemos blogs y le dedicamos horas a investigar, preparar artículos, responder las preguntas de los comentarios,... lo hacemos porque nos gusta y nos apetece. Si fuera una obligación o una carga, o no lo haríamos o lo llevaríamos muchísimo peor y al final se notaría en la cantidad y la calidad de los artículos.
Con estas premisas, si además de hacer lo que te gusta y te apetece, puedes sacar algo a cambio, mejor, no?. Este blog tiene una temática definida (aunque empezó siendo un blog personal en el que contaba lo que me pasaba por la cabeza), por lo que no estoy dispuesto a aceptar ningún análisis patrocinado que no pueda aportar algo a los lectores. Me han llegado solicitudes de buscadores de vuelos, webs de poesía, hoteles en diversos puntos de España (en esta última semana más de 40 solicitudes),... y eso es algo por lo que no estoy dispuesto a pasar. Una cosa es sacar algún provecho y otra es venderte a lo que sea. Yo también leo muchos blogs y cuando me encuentro con un análisis patrocinado que no tiene nada que ver con la temática del blog me enfado bastante.
Por otro lado está el tema de la publicidad. Al principio este blog no tenía publicidad. Total, era un blog que no leía nadie y en el que escribía sobre cualquier tema. En este post se pueden observar las estadísticas de los primeros cuatro meses y son de pena. El cuarto mes tuve 221 visitantes únicos: ¡¡en todo un mes!!, cuando ahora la media está en torno a las 250-300 visitas diarias. Luego, en julio del año pasado, hablando con un amigo (Jose), después de salir en portada de barrapunto con el artículo del Raid 1 en linux, éste me dijo que como ya tenía más visitas, pusiera publicidad, que total, poquito a poco iría acumulando algo. Al final le hice caso, pero vamos, que tampoco es nada del otro mundo y no voy a poder dejar el trabajo para vivir del blog... ;-). Además el ritmo de publicación ha disminuido bastante últimamente porque estoy más liado en el curro y tengo menos tiempo libre en casa del que me gustaría. Ahora mismo estoy posteando desde un hotel de Spiez (Suiza) en el que llevo toda la semana por motivos de trabajo y en unas horas seguramente coja un avión de vuelta a España.
En definitiva, que voy a mantener la publicidad porque en algún momento me servirá para algún pequeño caprichito y los análisis patrocinados siempre que puedan os aportar algo a todos vosotros.
miércoles, 14 de mayo de 2008
Ocultar la ventana de "Equipo Bloqueado" en una Red Novell
Hace unos meses veíamos cómo ocultar la molesta ventana de "Equipo Bloqueado" cuando bloqueamos la sesión en windows. La red de la empresa en la que trabajo es un tanto peculiar y esta semana nos han instalado el cliente Novell para poder acceder a recursos compartidos en dicha red (aunque también seguimos iniciando la sesión en el dominio Windows). Esto ha provocado que que las ventanas de inicio de sesión, cambio de contraseña, bloqueo del equipo,... hayan cambiado por las nuevas del cliente Novell. Así, cuando bloqueamos el equipo volvemos a tener una fea ventana que tapa nuestra foto de fondo de pantalla.
Después de investigar cual es la dll en la que se encuentra la ventana llego a este foro en el que alguien pregunta por dicha dll, que finalmente resulta ser C:\WINDOWS\system32\nls\ESPANOL\nwginar.dll. Abro el ResourceHacker, encuentro el diálogo, cambio el código por el siguiente:
Posteriormente salvo la dll, con la consola de recuperación hago el cambio y en poco más de 10 minutos y dos reinicios vuelvo a ver la foto de mi peque a ventana completa sin la molesta ventana quedando algo parecido a esto:
P.D: Para ver una explicación detallada de los pasos consultar el post anterior para ocultar la ventana en windows.
Después de investigar cual es la dll en la que se encuentra la ventana llego a este foro en el que alguien pregunta por dicha dll, que finalmente resulta ser C:\WINDOWS\system32\nls\ESPANOL\nwginar.dll. Abro el ResourceHacker, encuentro el diálogo, cambio el código por el siguiente:
105 DIALOG 0, 0, 0, 0
STYLE WS_POPUP | WS_VISIBLE
CAPTION ""
LANGUAGE LANG_SPANISH, 0x1
FONT 0, ""
{
}
Posteriormente salvo la dll, con la consola de recuperación hago el cambio y en poco más de 10 minutos y dos reinicios vuelvo a ver la foto de mi peque a ventana completa sin la molesta ventana quedando algo parecido a esto:
 |
P.D: Para ver una explicación detallada de los pasos consultar el post anterior para ocultar la ventana en windows.
miércoles, 7 de mayo de 2008
Actualizando a Hardy Heron
Por fin he tenido tiempo para actualizar mi versión de Ubuntu a Hardy Heron. Después de más de 1 Gbyte de paquetes para descargar y casi 2 horas actualizando, reinicié la máquina y tuve el primer fallo. Me cargaba el entorno gráfico pero nunca salía la ventana de login, se quedaba el reloj dando vueltas y vueltas. Lo primero que se me ocurrió fue cambiarme de terminal con CRTL + ALT + F1, conectarme con mi usuario y reiniciar GDM. El resultado fue el mismo. Lo siguiente fue pararlo y entrar en modo gráfico con el mítico startx. En ese caso sí arrancaba y todo funcionaba a la perfección. El error sólo podía ser del GDM, así que después de buscar un rato llegué a este enlace en el que a más gente le ocurría lo mismo. Al final, la solución la encontré aquí. Finalmente, lo que pasaba era que había un problema con el paquete ubuntu-gdm-themes y no funcionaba correctamente con algunas configuraciones. En mi caso era porque tenía instalado un tema para el gdm distinto al original y parecía que no era compatible. Lo arreglé y cambié el tema y todo solucionado.
Otro pequeño problema ha sido con Firefox 3. La versión que han incluído por defecto en Hardy ha sido la beta 5, lo que desde mi punto de vista no ha sido muy acertado. La he probado un rato y se nota la velocidad, pero la mayoría de las extensiones que utilizo no funcionan todavía en firefox 3, por lo que he tenido que desinstalar ésta e instalar la antigua 2.0.0.14.
El resto han sido todo cosas buenas. Noto que el sistema va mucho más ligero y fluído. Los programas cargan antes y todo es mucho más rápido en general. Además la nueva versión de CompizFusion es rápida y estable y ha solucionado un pequeño problema que tenía con la versión anterior que no me guardaba algunos cambios. A falta de trabajar más días con esta nueva versión, mis primeras impresiones son muy satisfactorias y se ha mejorado bastante respecto a gutsy. Ahora ya sólo me queda compilar el kernel a mi gusto, probar la webcam usb, el infrarrojo y terminar de afinar un poco la configuración para dejarlo todo adaptado a mi gusto.
Otro pequeño problema ha sido con Firefox 3. La versión que han incluído por defecto en Hardy ha sido la beta 5, lo que desde mi punto de vista no ha sido muy acertado. La he probado un rato y se nota la velocidad, pero la mayoría de las extensiones que utilizo no funcionan todavía en firefox 3, por lo que he tenido que desinstalar ésta e instalar la antigua 2.0.0.14.
El resto han sido todo cosas buenas. Noto que el sistema va mucho más ligero y fluído. Los programas cargan antes y todo es mucho más rápido en general. Además la nueva versión de CompizFusion es rápida y estable y ha solucionado un pequeño problema que tenía con la versión anterior que no me guardaba algunos cambios. A falta de trabajar más días con esta nueva versión, mis primeras impresiones son muy satisfactorias y se ha mejorado bastante respecto a gutsy. Ahora ya sólo me queda compilar el kernel a mi gusto, probar la webcam usb, el infrarrojo y terminar de afinar un poco la configuración para dejarlo todo adaptado a mi gusto.
 |
domingo, 27 de abril de 2008
La informática de antaño
Estaba haciendo limpieza el otro día en el trastero y al abrir un par de cajas me he encontrado con todo tipo de hardware que me ha hecho recordar cómo era todo en el mundo de la informática hace algunos años. Me he decidido a hacer unas cuantas fotos y a recordar...
Tarjetas perforadas: Datan de los años 1960-1970 y se utilizaban para introducir instrucciones en los ordenadores. Actuan como un código binario en función de si están perforadas o no. Como véis tengo unas cuantas, en total hay 25 perforadas y 4 vírgenes. He querido destacar un fragmento de código de una tarjeta en la que se ve una fecha: 31 de Marzo de 1981, seguramente era para sacar un listado a final de mes. Por aquel entonces sólo utilizaron la fecha con formato 31.03.81 y no se preocuparon de lo que ocurriría en el año 2000... ;-)
He hablado con mi padre puesto que las tarjetas eran suyas y las utilizó en el trabajo hace mucho y me ha contado que tenían una especie de máquina de escribir en la que tecleaban la instrucción en Cobol y cuando la terminaban la máquina perforaba la tarjeta. Así, iban construyendo el programa línea a línea y al final colocaban todas las tarjetas en un alimentador de hasta 5000 tarjetas que se encarga de leerlas e ir ejecutando el programa. Estos programas corrían contra un host IBM 3090 que estaba en Alemania (mi padre trabajaba desde Madrid). He buscado información de esa máquina y para aquella época era impresionante: dos o cuatro procesadores y 64 ó 128 MB de almacenamiento (según modelo). Y estamos hablando de principios de los 80!.
Disquetes 8": Los empezó a utilizar IBM a finales de los 60 para cargar el microcódigo de arranque en sus mainframes System/370. Antes de disponer de esta unidad de disco utilizaban unidades de cinta para realizar esta carga, pero el proceso era muy lento. Si os fijáis en el de la izquiera, podéis ver que la capacidad era de sólo 1024 bytes, es decir, un "miserable" Kbyte!!.
Disquetes 5.25": El primer prototipo se diseñó en 1975 y surgió por la necesidad de cambiar los discos de 8" que resultaban demasiado grandes. Seguramente los más viejos del lugar recuerden las disqueteras de sus primeros 8086 y la "gran cantidad de información" que podíamos almacenar en estos disquetes. En las fotos véis que la capacidad había aumentado considerablemente, yo tenía de 360 KBytes y de 1.2 MBytes. El disquete de arriba a la derecha es la versión 3.21 de D.O.S.
Disquetes de 3.5": Surgieron a mediados de los 80 como sustitutos de los de 5.25". Por aquel entonces éstos últimos ya no resultaban nada prácticos y además se podían estropear con mucha facilidad. Así, después de diversos formatos e intentos por reducir el tamaño se llegó a los discos de 3.5" que todos conocemos. Las ventajas eran innumerables: formato mucho más pequeño, más capacidad debido al rediseño que se hizo, estaban protegidos por una pequeña chapita,... De estos seguro que sí os acordáis todos. Como podéis ver tengo unas cuantas cajas con juegos clásicos (Monkey Island, Doom, Maniac Mansion,...), multitud de programas (WordPerfect, dBase III,...), discos de arranque... grabados en disquetes de 3.5" y la mayoría comprimidos con el mítico ARJ.
Platos de disco duro: Aunque seguro que la mayoría ha desarmado algún que otro disco duro, los platos de abajo son los normales de discos duros de 3.5" y los de arriba son de discos duros mucho más antiguos. Seguramente no tenían ni siquiera 20 MBytes de capacidad, por lo que os podéis hacer una idea de cuando serán.
Placa de 486: Esta es la placa de un 486DX 50Mhz. Como véis por aquel entonces no había slots PCI y lo máximo eran los nuevos slots VESA Local Bus que creo que nunca llegué a utilizar.
Memorias SIMM de 30 contactos: Las que utilizaba en la placa anterior con mi 486. Empecé con 4 Mbytes cuando me compré el ordenador pero un año después lo amplié con 8 MBytes más. Con esos 12 Mbytes era capaz de ejecutar todos los juegos nuevos sin ningún problema y el ordenador iba muy fluido. Todavía conservo 16 módulos (recordad que iban de 2 en 2) de diversos tamaños que en total suman 152 MBytes de RAM.
Tarjetas gráficas ATI Mach: Todavía conservo un par de tarjetas gráficas de la época. La de abajo es una ATI Mach32 ISA y la de arriba una ATI Mach64 PCI. ¡Qué buenos ratos me hicieron pasar las dos!.
Tarjetas de red: Todas 3Com de diversos modelos. Las de la izquierda son de 10 MBits/seg y conexión ISA, las inferiores de 10 Mbits/seg y conexión PCI y las superiores de 100 Mbits/seg y conexión PCI.
Tarjetas de sonido: Las míticas Sound Blaster AWE 64. ¿Quién no ha tenido una Sound Blaster en su máquina?.
Controladora SCSI: Tiene conexión ISA y creo que nunca la llegué a utilizar, tengo poco que añadir...
Unidad de cinta: En la época de los discos duros de 120MB que parecía que nunca los ibas a llenar y que al final terminaban llenos de juegos (de MS-DOS, claro). La unidad de cinta era perfecta para poder hacer backups de tus juegos y los pocos datos que se acumulaban por aquel entonces. La capacidad era abrumadora porque en una sóla cinta entraban 340MB!. Tenía una unidad externa que se conectaba al puerto de paralelo y posteriormente me hice con esta interna que se conectaba al cable de la disquetera. Las transferencias eran bastante lentas pero podías dejar el backup lanzado y cuando volvías tenías todo tu disco duro en una pequeña cinta.
Cintas de backup: Como ya he comentado tenían 340 Mbytes de capacidad que incluso se podían duplicar si los backups se hacían con la compresión habilitada.
Pentium MMX: Este micro fue una mejora realizada a los primeros Pentium que les añadía las Multimedia Extensions.
Pentium Pro: Fue el procesador diseñado por intel para reemplazar a los Pentium originales. Se utilizó básicamente en servidores y estaciones de trabajo de alto rendimiento y su característica principal es que estaba diseñado para poder montarse en placas bi-procesador.
Placa Pentium 2: Esta era mi placa para el pentium 2 a 300 Mhz que tuve. Esta placa ya llevaba memoria SDRAM, tenía slots PCI e ISA y además introducía el AGP para la conexión de la tarjeta gráfica. Este ordenador me estuvo acompañando muchos años y todavía funciona. En la entrada Servidor Raid 1 en Preproducción de marzo de 2007 comentaba que lo había montado de nuevo para hacer una prueba del raid 1 en linux con hardware real.
Pentium 2: Intel creó este micro después del Pentium Pro. La principal característica que más llamaba la atención era su enorme tamaño y su encapsulado. Era algo totalmente distinto a lo que estábamos acostumbrados a ver.
Memoria SDRAM: Este tipo de memorias ya no era necesario montarlas de 2 en 2 y fueron las precursoras de las actuales DDR, DDR2,.... Se podían mezclar de cualquier tamaño y funcionaban sin problemas. La mayoría de los módulos que tengo funcionan y en total suman 896 MBytes de RAM repartidos en los 10 módulos que se ven.
Tarjetas PCMCIA: El principal uso de este tipo tarjetas es para utilizarlas como expansión en los portátiles. Así, en los tiempos en que éstos no tenían ni modem ni tarjeta de red integrados con una simple tarjeta pcmcia se podían ampliar. Este tipo de tarjetas se podían conectar y desconectar en caliente (el famoso plug&play).
Discos duros: En total tengo 14 discos duros IDE de los que seguramente no debe funcionar casi ninguno. Son discos muy antiguos y su capacidad va desde los 850 MBytes a los 4.2 GBytes. Los fabricantes son Seagate, Sansumg, Quantum y Fujitsu.
A todo esto que habéis visto hay que añadirle multitud de cables IDE, cable de red, conectores DB25 y DE9 desarmados y listos para soldar en un cable, cables de audio de los que se conectaban a la tarjeta de sonido y al lector de cd's, algún lector de cd's y grabadora antigua, tres modems de 33.6 bps y 56 bps... y diverso hardware más.
Quiero dar las gracias a mi padre que ha estado muchos años dedicándose a esto y gracias al cual he podido estar cerca de todo lo que acabáis de ver. Muchas veces he pensado que si él hubiese sido albañil, fontanero, mecánico... en lugar de informático, yo no habría llegado donde estoy ni tendría esta pasión y afición que tengo por la informática. ¡Muchas gracias papá!.
Además, tampoco me olvido de mi mujer por dejarme conservar todas estas reliquias y cacharros viejos como los llama ella en el trastero...
Tarjetas perforadas: Datan de los años 1960-1970 y se utilizaban para introducir instrucciones en los ordenadores. Actuan como un código binario en función de si están perforadas o no. Como véis tengo unas cuantas, en total hay 25 perforadas y 4 vírgenes. He querido destacar un fragmento de código de una tarjeta en la que se ve una fecha: 31 de Marzo de 1981, seguramente era para sacar un listado a final de mes. Por aquel entonces sólo utilizaron la fecha con formato 31.03.81 y no se preocuparon de lo que ocurriría en el año 2000... ;-)
He hablado con mi padre puesto que las tarjetas eran suyas y las utilizó en el trabajo hace mucho y me ha contado que tenían una especie de máquina de escribir en la que tecleaban la instrucción en Cobol y cuando la terminaban la máquina perforaba la tarjeta. Así, iban construyendo el programa línea a línea y al final colocaban todas las tarjetas en un alimentador de hasta 5000 tarjetas que se encarga de leerlas e ir ejecutando el programa. Estos programas corrían contra un host IBM 3090 que estaba en Alemania (mi padre trabajaba desde Madrid). He buscado información de esa máquina y para aquella época era impresionante: dos o cuatro procesadores y 64 ó 128 MB de almacenamiento (según modelo). Y estamos hablando de principios de los 80!.
 |  |
Disquetes 8": Los empezó a utilizar IBM a finales de los 60 para cargar el microcódigo de arranque en sus mainframes System/370. Antes de disponer de esta unidad de disco utilizaban unidades de cinta para realizar esta carga, pero el proceso era muy lento. Si os fijáis en el de la izquiera, podéis ver que la capacidad era de sólo 1024 bytes, es decir, un "miserable" Kbyte!!.
 |
Disquetes 5.25": El primer prototipo se diseñó en 1975 y surgió por la necesidad de cambiar los discos de 8" que resultaban demasiado grandes. Seguramente los más viejos del lugar recuerden las disqueteras de sus primeros 8086 y la "gran cantidad de información" que podíamos almacenar en estos disquetes. En las fotos véis que la capacidad había aumentado considerablemente, yo tenía de 360 KBytes y de 1.2 MBytes. El disquete de arriba a la derecha es la versión 3.21 de D.O.S.
 |
Disquetes de 3.5": Surgieron a mediados de los 80 como sustitutos de los de 5.25". Por aquel entonces éstos últimos ya no resultaban nada prácticos y además se podían estropear con mucha facilidad. Así, después de diversos formatos e intentos por reducir el tamaño se llegó a los discos de 3.5" que todos conocemos. Las ventajas eran innumerables: formato mucho más pequeño, más capacidad debido al rediseño que se hizo, estaban protegidos por una pequeña chapita,... De estos seguro que sí os acordáis todos. Como podéis ver tengo unas cuantas cajas con juegos clásicos (Monkey Island, Doom, Maniac Mansion,...), multitud de programas (WordPerfect, dBase III,...), discos de arranque... grabados en disquetes de 3.5" y la mayoría comprimidos con el mítico ARJ.
 |
Platos de disco duro: Aunque seguro que la mayoría ha desarmado algún que otro disco duro, los platos de abajo son los normales de discos duros de 3.5" y los de arriba son de discos duros mucho más antiguos. Seguramente no tenían ni siquiera 20 MBytes de capacidad, por lo que os podéis hacer una idea de cuando serán.
 |
Placa de 486: Esta es la placa de un 486DX 50Mhz. Como véis por aquel entonces no había slots PCI y lo máximo eran los nuevos slots VESA Local Bus que creo que nunca llegué a utilizar.
 |
Memorias SIMM de 30 contactos: Las que utilizaba en la placa anterior con mi 486. Empecé con 4 Mbytes cuando me compré el ordenador pero un año después lo amplié con 8 MBytes más. Con esos 12 Mbytes era capaz de ejecutar todos los juegos nuevos sin ningún problema y el ordenador iba muy fluido. Todavía conservo 16 módulos (recordad que iban de 2 en 2) de diversos tamaños que en total suman 152 MBytes de RAM.
 |
Tarjetas gráficas ATI Mach: Todavía conservo un par de tarjetas gráficas de la época. La de abajo es una ATI Mach32 ISA y la de arriba una ATI Mach64 PCI. ¡Qué buenos ratos me hicieron pasar las dos!.
 |
Tarjetas de red: Todas 3Com de diversos modelos. Las de la izquierda son de 10 MBits/seg y conexión ISA, las inferiores de 10 Mbits/seg y conexión PCI y las superiores de 100 Mbits/seg y conexión PCI.
 |
Tarjetas de sonido: Las míticas Sound Blaster AWE 64. ¿Quién no ha tenido una Sound Blaster en su máquina?.
 |
Controladora SCSI: Tiene conexión ISA y creo que nunca la llegué a utilizar, tengo poco que añadir...
 |
Unidad de cinta: En la época de los discos duros de 120MB que parecía que nunca los ibas a llenar y que al final terminaban llenos de juegos (de MS-DOS, claro). La unidad de cinta era perfecta para poder hacer backups de tus juegos y los pocos datos que se acumulaban por aquel entonces. La capacidad era abrumadora porque en una sóla cinta entraban 340MB!. Tenía una unidad externa que se conectaba al puerto de paralelo y posteriormente me hice con esta interna que se conectaba al cable de la disquetera. Las transferencias eran bastante lentas pero podías dejar el backup lanzado y cuando volvías tenías todo tu disco duro en una pequeña cinta.
 |
Cintas de backup: Como ya he comentado tenían 340 Mbytes de capacidad que incluso se podían duplicar si los backups se hacían con la compresión habilitada.
 |
Pentium MMX: Este micro fue una mejora realizada a los primeros Pentium que les añadía las Multimedia Extensions.
 |
Pentium Pro: Fue el procesador diseñado por intel para reemplazar a los Pentium originales. Se utilizó básicamente en servidores y estaciones de trabajo de alto rendimiento y su característica principal es que estaba diseñado para poder montarse en placas bi-procesador.
 |
Placa Pentium 2: Esta era mi placa para el pentium 2 a 300 Mhz que tuve. Esta placa ya llevaba memoria SDRAM, tenía slots PCI e ISA y además introducía el AGP para la conexión de la tarjeta gráfica. Este ordenador me estuvo acompañando muchos años y todavía funciona. En la entrada Servidor Raid 1 en Preproducción de marzo de 2007 comentaba que lo había montado de nuevo para hacer una prueba del raid 1 en linux con hardware real.
 |
Pentium 2: Intel creó este micro después del Pentium Pro. La principal característica que más llamaba la atención era su enorme tamaño y su encapsulado. Era algo totalmente distinto a lo que estábamos acostumbrados a ver.
 |
Memoria SDRAM: Este tipo de memorias ya no era necesario montarlas de 2 en 2 y fueron las precursoras de las actuales DDR, DDR2,.... Se podían mezclar de cualquier tamaño y funcionaban sin problemas. La mayoría de los módulos que tengo funcionan y en total suman 896 MBytes de RAM repartidos en los 10 módulos que se ven.
 |
Tarjetas PCMCIA: El principal uso de este tipo tarjetas es para utilizarlas como expansión en los portátiles. Así, en los tiempos en que éstos no tenían ni modem ni tarjeta de red integrados con una simple tarjeta pcmcia se podían ampliar. Este tipo de tarjetas se podían conectar y desconectar en caliente (el famoso plug&play).
 |
Discos duros: En total tengo 14 discos duros IDE de los que seguramente no debe funcionar casi ninguno. Son discos muy antiguos y su capacidad va desde los 850 MBytes a los 4.2 GBytes. Los fabricantes son Seagate, Sansumg, Quantum y Fujitsu.
 |
A todo esto que habéis visto hay que añadirle multitud de cables IDE, cable de red, conectores DB25 y DE9 desarmados y listos para soldar en un cable, cables de audio de los que se conectaban a la tarjeta de sonido y al lector de cd's, algún lector de cd's y grabadora antigua, tres modems de 33.6 bps y 56 bps... y diverso hardware más.
Quiero dar las gracias a mi padre que ha estado muchos años dedicándose a esto y gracias al cual he podido estar cerca de todo lo que acabáis de ver. Muchas veces he pensado que si él hubiese sido albañil, fontanero, mecánico... en lugar de informático, yo no habría llegado donde estoy ni tendría esta pasión y afición que tengo por la informática. ¡Muchas gracias papá!.
Además, tampoco me olvido de mi mujer por dejarme conservar todas estas reliquias y cacharros viejos como los llama ella en el trastero...
jueves, 17 de abril de 2008
Un diez para el SAT de Rimax
Hace un año mi hermana nos regaló una cámara de vigilancia de bebés para que la tuviéramos lista para cuando naciera Judith. Durante todo este tiempo la hemos estado usando por las noches para vigilarla por si se despierta, llora o le pasa cualquier cosa. Es muy útil y práctica porque no te tienes que levantar de la cama y puedes ver en cualquier momento cómo se encuentra.
El caso es que la semana pasada se nos estropeó el adaptador de corriente de la cámara y con las pilas casi seguro que no nos duraba encendida toda la noche. Miramos en la web de Rimax en el apartado de garantías y el servicio que ofrecen es de lo mejor. Te dan 2 años completos de garantía para todos sus productos. Se compromenten a recogerlo en tu casa, repararlo o sustituirlo por uno nuevo en caso de no poder hacerlo y enviártelo de nuevo a casa sin ningún coste adicional. Al día siguiente de tramitar la garantía se pusieron en contacto conmigo por email solicitando una copia del ticket para comprobar la fecha de compra. Me dijeron que les indicara claramente cual era el cargador que fallaba (cámara o monitor) y que me enviarían uno nuevo. Como el del monitor también me fallaba a veces les pedí los dos. En dos días llegó por mensajería un paquete con los dos cargadores nuevos y desde entonces ya podemos usar de nuevo la cámara por las noches.
Cuando elegimos la cámara no conocíamos el excelente servicio post-venta que tiene Rimax. Esto ha hecho que a partir de ahora, cuando tenga que comprar cualquier gadget mire si Rimax tiene algo que me interese, porque es una marca que voy a tener muy en cuenta en el futuro. Escribiendo este post me he acordado de las peleas que tuve durante casi 6 meses con Panasonic por un móvil que le regalé a mi mujer hace más de 4 años, pero esa es una historia para otro post...
El caso es que la semana pasada se nos estropeó el adaptador de corriente de la cámara y con las pilas casi seguro que no nos duraba encendida toda la noche. Miramos en la web de Rimax en el apartado de garantías y el servicio que ofrecen es de lo mejor. Te dan 2 años completos de garantía para todos sus productos. Se compromenten a recogerlo en tu casa, repararlo o sustituirlo por uno nuevo en caso de no poder hacerlo y enviártelo de nuevo a casa sin ningún coste adicional. Al día siguiente de tramitar la garantía se pusieron en contacto conmigo por email solicitando una copia del ticket para comprobar la fecha de compra. Me dijeron que les indicara claramente cual era el cargador que fallaba (cámara o monitor) y que me enviarían uno nuevo. Como el del monitor también me fallaba a veces les pedí los dos. En dos días llegó por mensajería un paquete con los dos cargadores nuevos y desde entonces ya podemos usar de nuevo la cámara por las noches.
Cuando elegimos la cámara no conocíamos el excelente servicio post-venta que tiene Rimax. Esto ha hecho que a partir de ahora, cuando tenga que comprar cualquier gadget mire si Rimax tiene algo que me interese, porque es una marca que voy a tener muy en cuenta en el futuro. Escribiendo este post me he acordado de las peleas que tuve durante casi 6 meses con Panasonic por un móvil que le regalé a mi mujer hace más de 4 años, pero esa es una historia para otro post...
lunes, 7 de abril de 2008
¿OOXML?... No, gracias

Se ha hablado y escrito mucho la semana pasada sobre la aprobación de OOXML por parte de ISO como estándar. En los medios más importantes se recogen numerosos comentarios, críticas, lamentos,...
Se habló tanto en slashdot como en barrapunto de la aprobación por parte de ISO. Kriptópolis también se hizo eco de la noticia y posteriormente se conocieron la manipulación de Polonia y las irregularidades de Noruega.
A partir de ahí han habido numerosas declaraciones. Uno de los que más duramente han cargado contra ISO y OOXML ha sido Mark Shuttleworth (fundador de Ubuntu) que no se ha mordido la lengua.
Pienso que devalúa la confianza que las personas tienen en los procesos de estandarización. Es triste que ISO no quiera admitir que todo el proceso ha fallado gravemente. Cuando tienes un proceso construido sobre la verdad y cuando se abusa de esa verdad, el proceso se debería parar.
Y para finalizar Rosa García, presidenta de Microsoft España nos sorprendió el pasado viernes con esta entrada en su blog. Desde su posición es lógico que tenga que defender OOXML, pero clama al cielo lo que comenta en el artículo. De hecho, lo leí el viernes por la noche y no tuve más remedio que contestarle en su blog:
Iván
04 abril 23:52
(http://lopezivan.blogspot.com)
¡Qué fuerte me parecen estas palabras!
Todo el mundo sabe que lo único que quería conseguir Microsoft con la estandarización es obligar a todo el mundo a usar su formato. Vale que dices: "...tras el último anuncio de interoperabilidad de Microsoft, a corto plazo será posible “guardar como” ODF desde cualquier aplicación de Office por defecto si así se desea."
Quien va a usar eso?. El usuario de "a pie" no sabe nada de formatos ni tiene idea de nada. Si cuando va a guardar su documento el formato que aparece por defecto es ooxml, pues ese será con el que se guardará.
Otro: "El estándar presenta algunas limitaciones en diversos aspectos, como la gestión de fórmulas en hojas de cálculo o las funcionalidades de accesibilidad, para garantizar que las personas con discapacidad puedan utilizar los documentos en formato ODF pero, en cualquier caso, Microsoft no se opuso en su momento a la estandarización de ODF".
Comentas que existen muchos formatos de imágenes, de compresión de videos,... y que ODF tiene algunas limitaciones. La solución pasa por una revisión del estándar ya existente, no por hacer uno nuevo.
Otra perla: "El proceso de estandarización de Open XML ha sido transparente y ha cumplido todos los requerimientos de ISO. El estándar se ha aprobado por mayoría absoluta, con el apoyo del 86% de los países miembros de ISO. Por encima de cualquier otro condicionante, el respaldo de la gran mayoría de los países representados en ISO demuestra que la lógica técnica es la que finalmente se impone."
Toda la blogosfera y muchísimos medios se han hecho eco de lo que ha ocurrido con las votaciones y cómo se han amañado. ¿Cómo es posible casos como el de Noruega que con 19 votos en contra y sólo 5 a favor, el país vote sí?. Está claro, se han movido maletines y se ha sobornado a mucha gente.
Más: "Desde el momento en que ECMA e ISO aprueban el formato Open XML como estándar internacional, Microsoft deja de controlar este formato, que pasa ahora a depender de los cuerpos de estandarización internacionales".
No nos engañemos, con esas 6000 páginas de especificación, muy pocas empresas distintas a Microsoft van a ser capaces de implementar completamente el formato, por lo que al final, sólo serán los productos de Microsoft los que lo puedan utilizar bien.
Entiendo que tienes que defender a tu compañía pero hay cosas que comentas que no son normales. En fin...
Saludos, Iván.
Para finalizar, yo lo tengo muy claro. No pienso instalarme office 2007 (todavía utilizo el 2000 las pocas veces que entro en windows) y no pienso utilizar ooxml. Convertiré todos mis documentos a ODF y haré "campaña" con familiares y amigos para que utilicen ODF en lugar de ooxml.
¿Alguien piensa qué ocurrirá con sus documentos dentro de 15, 20 ó 50 años si están todos bajo control de Microsoft?. Yo no pienso pasar por el aro. Cuando la gente empiece a instalarse masivamente el office 2007 en sus casas (pirata, por supuesto) y empiecen a enviar las típicas chorradas en ooxml, simplemente les responderé a su email diciendo que si desean que ese documento lo pueda utilizar todo el mundo, lo conviertan y lo envíen con un estándar de verdad como es ODF y no con otro conseguido a golpe de talonario. Eliminaré el email y listo, una chorrada menos.
martes, 1 de abril de 2008
Convertir un raid 1 a un raid 5 sin formatear
Hace un mes Javier Ros me contaba que se había montado un servidor Ubuntu en casa con un raid 1 para almacenar sus datos siguiendo mi artículo del Raid 1 en Linux. En ese mismo comentario me planteaba que se le estaba llenando el raid y que en lugar de hacer un nuevo raid 1 (puesto que necesitaba dos discos adicionales) había pensado en hacer un raid 5 añadiendo solamente un disco más. Así, me pasaba un enlace que había encontrado en el que se muestra cómo pasar de un raid 1 a un raid 5 sin necesidad de formatear y sin perder la información.
Como sabéis, no me creo las cosas si no las pruebo. Además he estado buscando información sobre cómo funciona un raid 5 y cómo puede ser posible hacer el cambio sin perder los datos. Así, en este artículo vamos a ver un poco de teoría, posteriormente la conversión de un raid 1 a raid 5 siguiendo el tutorial inicial añadiendo mis propios comentarios, y finalmente mis impresiones sobre el raid 5.
Un poco de Teoría
Un raid 5 es la evolución lógica de un raid 4. Divide los datos en bloques y distribuye la paridad entre el total de discos del raid. Así, se elimina el problema del raid 4 de tener la paridad en un único disco y que éste se convierta en un cuello de botella. Este tipo de raid tiene una tolerancia a los fallos de un disco. Si uno falla el raid puede seguir funcionando y cuando se reemplaza el disco que ha fallado, se puede reconstruir la información que falta partiendo de la existente en el resto de discos.
El cálculo de la paridad se realiza con la función lógica XOR cuya característica es que devuelve 1 si los bits de entrada son diferentes y 0 si son iguales. Esta es una característica muy importante puesto hace que dicha función sea reversible. Veámoslo con un ejemplo para que quede más claro:
Como hemos dicho, la función es reversible, por lo que si "le damos la vuelta":
Es decir, que partiendo de A y teniendo la paridad podemos calcular B. Esta propiedad también se aplica a A XOR B XOR C XOR D ... XOR N = PARIDAD, de manera que si tenemos un raid de N discos y falla cualquiera, la información que falta se puede calcular sin problemas partiendo del resto de datos y de la paridad.
El truco para realizar la conversión consiste en que si aplicamos dicho algoritmo a dos discos, lo que obtenemos es que los dos discos se quedan en espejo!. Esto es así porque la paridad de un único bloque es él mismo, debido a que el algorimo del raid 5 necesita al menos dos bloques. Así, la única diferencia entre un raid 1 de dos discos y un raid 5 de dos discos son los metadatos. Si reemplazamos estos metadatos convertiremos el raid 1 en un raid 5.
La parte práctica
Ahora ya sí, con la teoría aprendida vamos a realizar la conversión. Partimos de un sistema Debian ya instalado con un raid 1 creado con 2 discos y al 99% de su capacidad.
Desmontamos el raid y lo paramos.
Creamos el raid 5 con los dos dispositivos del raid 1 (sdf1 y sdg1).
Podemos observar cómo se reconstruye el raid y en la información detallada vemos que ya es un raid 5.
Ahora añadimos el nuevo disco para tener los 3 que queremos en el raid 5 y ampliamos el dispositivo. Podemos comprobar que se ha añadido el nuevo disco que se está redimensionando el raid.
Forzamos la comprobación del filesystem y lo redimensionamos.
Después de montar de nuevo el raid, comprobamos el nuevo tamaño (los 500MB del nuevo disco):
No se nos puede olvidar finalmente modificar el archivo /etc/mdadm.conf para que se actualicen los datos de nuestro nuevo raid 5.
Conclusiones
Hemos visto que es posible realizar la conversión de un raid 1 a un raid 5 sin perder los datos y sin necesidad de recrear el raid desde cero. Aún así, la pregunta es ¿merece la pena pasar a un raid 5?.
Depende. Para un entorno doméstico sin mucha carga y sin un uso muy intensivo yo diría que sí. La alternativa a tener un raid 5 pasa por un raid 10, pero en este caso ya necesitaríamos 4 discos en lugar de tres. La capacidad del volumen total sería la misma en ambos casos, pero para el raid 10 utilizaríamos un disco más!. En el lado positivo tendríamos dos discos de redundancia a fallos (uno de cada mirror), recuperaciones mucho más rápidas y mayor rendimiento.
Por contra, el principal problema del raid 5 es el tiempo de recuperación en caso de fallo de un disco y el pobre rendimiento que obtenemos cuando se está realizando dicha recuperación. De nuevo, en un entorno doméstico esto no debería representar mayor problema, pero aún así es un hecho a tener en cuenta antes de tomar la decisión final.
Como sabéis, no me creo las cosas si no las pruebo. Además he estado buscando información sobre cómo funciona un raid 5 y cómo puede ser posible hacer el cambio sin perder los datos. Así, en este artículo vamos a ver un poco de teoría, posteriormente la conversión de un raid 1 a raid 5 siguiendo el tutorial inicial añadiendo mis propios comentarios, y finalmente mis impresiones sobre el raid 5.
Un poco de Teoría
Un raid 5 es la evolución lógica de un raid 4. Divide los datos en bloques y distribuye la paridad entre el total de discos del raid. Así, se elimina el problema del raid 4 de tener la paridad en un único disco y que éste se convierta en un cuello de botella. Este tipo de raid tiene una tolerancia a los fallos de un disco. Si uno falla el raid puede seguir funcionando y cuando se reemplaza el disco que ha fallado, se puede reconstruir la información que falta partiendo de la existente en el resto de discos.
El cálculo de la paridad se realiza con la función lógica XOR cuya característica es que devuelve 1 si los bits de entrada son diferentes y 0 si son iguales. Esta es una característica muy importante puesto hace que dicha función sea reversible. Veámoslo con un ejemplo para que quede más claro:
| Binario | Decimal | |
| A | 11000110 | 198 |
| B | 00100101 | 37 |
| XOR | 11100011 | 227 |
Como hemos dicho, la función es reversible, por lo que si "le damos la vuelta":
| Binario | Decimal | |
| A | 11000110 | 198 |
| B | 11100011 | 227 |
| XOR | 00100101 | 37 |
Es decir, que partiendo de A y teniendo la paridad podemos calcular B. Esta propiedad también se aplica a A XOR B XOR C XOR D ... XOR N = PARIDAD, de manera que si tenemos un raid de N discos y falla cualquiera, la información que falta se puede calcular sin problemas partiendo del resto de datos y de la paridad.
El truco para realizar la conversión consiste en que si aplicamos dicho algoritmo a dos discos, lo que obtenemos es que los dos discos se quedan en espejo!. Esto es así porque la paridad de un único bloque es él mismo, debido a que el algorimo del raid 5 necesita al menos dos bloques. Así, la única diferencia entre un raid 1 de dos discos y un raid 5 de dos discos son los metadatos. Si reemplazamos estos metadatos convertiremos el raid 1 en un raid 5.
La parte práctica
Ahora ya sí, con la teoría aprendida vamos a realizar la conversión. Partimos de un sistema Debian ya instalado con un raid 1 creado con 2 discos y al 99% de su capacidad.
shian:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/md3 496M 464M 6.3M 99% /mnt/md3
shian:~# umount /dev/md3
shian:~# mdadm --stop /dev/md3
mdadm: stopped /dev/md3
shian:~# mdadm --create /dev/md3 --level=5 --raid-devices=2 /dev/sdf1 /dev/sdg1
mdadm: /dev/sdf1 appears to contain an ext2fs file system
size=524160K mtime=Wed Mar 26 16:43:27 2008
mdadm: /dev/sdf1 appears to be part of a raid array:
level=raid1 devices=2 ctime=Wed Mar 26 15:09:37 2008
mdadm: /dev/sdg1 appears to contain an ext2fs file system
size=524160K mtime=Wed Mar 26 16:43:27 2008
mdadm: /dev/sdg1 appears to be part of a raid array:
level=raid1 devices=2 ctime=Wed Mar 26 15:09:37 2008
Continue creating array? y
mdadm: array /dev/md3 started.
shian:~# cat /proc/mdstat
Personalities : [raid1] [raid6] [raid5] [raid4]
md3 : active raid5 sdg1[2] sdf1[0]
524160 blocks level 5, 64k chunk, algorithm 2 [2/1] [U_]
[=====>...............] recovery = 27.1% (143104/524160) finish=0.5min speed=11008K/sec
shian:~# mdadm --detail /dev/md3
/dev/md3:
Version : 00.90.03
Creation Time : Wed Mar 26 17:19:26 2008
Raid Level : raid5
Array Size : 524160 (511.96 MiB 536.74 MB)
Device Size : 524160 (511.96 MiB 536.74 MB)
Raid Devices : 2
Total Devices : 2
Preferred Minor : 3
Persistence : Superblock is persistent
Update Time : Wed Mar 26 17:20:16 2008
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 64K
UUID : df77ed88:83aa5bac:daa25bcf:b5b2c6e7
Events : 0.2
Number Major Minor RaidDevice State
0 8 81 0 active sync /dev/sdf1
1 8 97 1 active sync /dev/sdg1
shian:~# mdadm --add /dev/md3 /dev/sdh1
mdadm: added /dev/sdh1
shian:~# mdadm --grow /dev/md3 --raid-disks=3 --backup-file=/tmp/raid1-5.backup
mdadm: Need to backup 128K of critical section..
mdadm: ... critical section passed.
shian:~# cat /proc/mdstat
Personalities : [raid1] [raid6] [raid5] [raid4]
md3 : active raid5 sdh1[2] sdg1[1] sdf1[0]
524160 blocks super 0.91 level 5, 64k chunk, algorithm 2 [3/3] [UUU]
[=>...................] reshape = 8.3% (44544/524160) finish=2.6min speed=2969K/sec
shian:~# e2fsck -f /dev/md3
e2fsck 1.40-WIP (14-Nov-2006)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/md3: 20680/131072 files (0.6% non-contiguous), 491521/524160 blocks
shian:~# resize2fs -p /dev/md3
resize2fs 1.40-WIP (14-Nov-2006)
Resizing the filesystem on /dev/md3 to 1048320 (1k) blocks.
Begin pass 1 (max = 64)
Extending the inode table XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
The filesystem on /dev/md3 is now 1048320 blocks long.
shian:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/md3 992M 465M 476M 50% /mnt/md3
shian:~# cd /etc/mdadm
shian:/etc/mdadm# cp mdadm.conf mdadm.conf.`date +%y%m%d`
shian:/etc/mdadm# echo "DEVICE partitions" > mdadm.conf
shian:/etc/mdadm# mdadm --detail --scan >> mdadm.conf
Conclusiones
Hemos visto que es posible realizar la conversión de un raid 1 a un raid 5 sin perder los datos y sin necesidad de recrear el raid desde cero. Aún así, la pregunta es ¿merece la pena pasar a un raid 5?.
Depende. Para un entorno doméstico sin mucha carga y sin un uso muy intensivo yo diría que sí. La alternativa a tener un raid 5 pasa por un raid 10, pero en este caso ya necesitaríamos 4 discos en lugar de tres. La capacidad del volumen total sería la misma en ambos casos, pero para el raid 10 utilizaríamos un disco más!. En el lado positivo tendríamos dos discos de redundancia a fallos (uno de cada mirror), recuperaciones mucho más rápidas y mayor rendimiento.
Por contra, el principal problema del raid 5 es el tiempo de recuperación en caso de fallo de un disco y el pobre rendimiento que obtenemos cuando se está realizando dicha recuperación. De nuevo, en un entorno doméstico esto no debería representar mayor problema, pero aún así es un hecho a tener en cuenta antes de tomar la decisión final.
lunes, 24 de marzo de 2008
Un escritorio diferente
El otro día toqué por primera vez un windows vista. Un compañero del trabajo se compró un portatil nuevo y se lo llevó para enseñárnoslo. Quise ver el nuevo interfaz Aero y la verdad es que me pareció muy básico y pobre. Les comenté a mis compañeros que iba a hacer un video de mi escritorio de Linux para que vieran unos efectos de verdad con CompizFusion y sin necesidad de una máquina y una gráfica muy potentes. Sin más, este es el video:
Sé que muchos de estos efectos son pijadas, pero hay muchas opciones que son realmente útiles y sí que aumentan la productividad a la hora de trabajar.
Por supuesto todo el proceso de realización del video está realizado con software libre. La grabación la he hecho con XVidCap, para el montaje he utilizado KDEnlive y para añadir la música y redimensionar el video final mencoder.
Sé que muchos de estos efectos son pijadas, pero hay muchas opciones que son realmente útiles y sí que aumentan la productividad a la hora de trabajar.
Por supuesto todo el proceso de realización del video está realizado con software libre. La grabación la he hecho con XVidCap, para el montaje he utilizado KDEnlive y para añadir la música y redimensionar el video final mencoder.
jueves, 13 de marzo de 2008
Raid 1 en un sistema ya instalado
En el artículo del Raid 1 en linux veíamos cómo montar un raid 1 con Debian para tener fiablidad en nuestros datos y en el caso de que fallase un disco no perderlos. De esta forma aseguramos nuestros datos, pero en caso de fallo del disco de sistema irremediablemente tendríamos que instalar de nuevo todo.
Lo que vamos a ver en este artículo es cómo montar un raid 1 completo de todo el sistema Debian, con éste ya instalado y funcionando. De esta forma contesto a varias personas que me han pedido este artículo tanto en los comentarios del primero como por email. Para no hacer muy pesado el artículo obviaré algunas partes que están detalladas en el artículo anterior del raid 1, por lo que si algún paso no lo comprendes, por favor lee el artículo anterior para aclarar las dudas.
Debo aclarar que este tutorial está pensado para Debian y similares por lo que en otras distribuciones no funcionará correctamente al no existir el comando update-initramfs.
Partimos de un sistema ya instalado con tres particiones distintas: /dev/sda1 para /boot, /dev/sda5 para el swap y /dev/sda6 para /.
Después de añadir el disco a la máquina utilizamos el truco que ya usamos en el artículo original para copiar la tabla de particiones de un disco a otro:
Editamos con fdisk las particiones de /dev/sdb y cambiamos del tipo a fd de las número 1, 5 y 6. El resultado final es:
Ahora creamos los dispositivos raid para las particiones.
Formateamos las nuevas particiones.
Actualizamos el archivo mdadm.conf con los nuevos dispositivos raid.
Montamos las particiones del raid.
Editamos el archivo /etc/fstab y cambiamos sda1, sda5 y sda6 por los nuevos dispositivos del raid (md0, md1 y md2 respectivamente).
Editamos el archivo /boot/grub/menu.lst de configuración del grub para añadir las entradas a ambos discos duros. Duplicamos la línea que tenemos del arranque, cambiamos sda6 por md2 y cambiamos el disco duro del que arranca.
Ahora actualizamos el ramdisk para que se reflejen los cambios que hemos hecho.
Copiamos los datos de las particiones antiguas a las nuevas del raid. La opción 'x' es muy importante porque sino al copiar desde / copiaríamos todo de manera recursiva.
Instalamos y reconfiguramos grub en los dos discos.
Y ya podemos reinicar la máquina. Hay que tenemos en cuenta que la máquina sólo arrancará del segundo disco porque el primero todavía no forma parte del raid. Si todo va bien, una vez que arranque veremos algo como esto:
Lo más difícil ya está hecho. Tenemos el raid funcionando en modo degradado porque sólo está disponible el disco sdb. Ahora repetimos casi el mismo proceso para el disco antiguo. Cambiamos el tipo de particiones a fd y las añadimos particiones al raid.
Empezará entonces la reconstrucción de los raid.
Un vez terminada la reconstrucción tendremos listo el sistema. Ahora, si queremos probar que todo funciona correctamente podemos reinicar de nuevo la máquina y comprobar que es capaz de arrancar desde cualquiera de los dos discos.
Con este tipo de configuración estamos seguros de que aunque falle un disco nuestro servidor estará disponible y no tendremos que reinstalar ni reconfigurar nada. Sólo será necesario cambiar el disco defectuoso, reconstruir el raid y reconfigurar el grub.
Lo que vamos a ver en este artículo es cómo montar un raid 1 completo de todo el sistema Debian, con éste ya instalado y funcionando. De esta forma contesto a varias personas que me han pedido este artículo tanto en los comentarios del primero como por email. Para no hacer muy pesado el artículo obviaré algunas partes que están detalladas en el artículo anterior del raid 1, por lo que si algún paso no lo comprendes, por favor lee el artículo anterior para aclarar las dudas.
Debo aclarar que este tutorial está pensado para Debian y similares por lo que en otras distribuciones no funcionará correctamente al no existir el comando update-initramfs.
Partimos de un sistema ya instalado con tres particiones distintas: /dev/sda1 para /boot, /dev/sda5 para el swap y /dev/sda6 para /.
Filesystem Size Used Avail Use% Mounted on
/dev/sda6 7.4G 509M 6.5G 8% /
tmpfs 63M 0 63M 0% /lib/init/rw
udev 10M 84K 10M 1% /dev
tmpfs 63M 0 63M 0% /dev/shm
/dev/sda1 177M 11M 157M 7% /boot
shian:~# sfdisk -d /dev/sda | sfdisk /dev/sdb
Checking that no-one is using this disk right now ...
OK
Disk /dev/sdb: 1044 cylinders, 255 heads, 63 sectors/track
sfdisk: ERROR: sector 0 does not have an msdos signature
/dev/sdb: unrecognized partition table type
Old situation:
No partitions found
New situation:
Units = sectors of 512 bytes, counting from 0
Device Boot Start End #sectors Id System
/dev/sdb1 63 385559 385497 83 Linux
/dev/sdb2 385560 16771859 16386300 5 Extended
/dev/sdb3 0 - 0 0 Empty
/dev/sdb4 0 - 0 0 Empty
/dev/sdb5 385623 1172744 787122 82 Linux swap / Solaris
/dev/sdb6 1172808 16771859 15599052 83 Linux
...
Command (m for help): p
Disk /dev/sdb: 8589 MB, 8589934592 bytes
255 heads, 63 sectors/track, 1044 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdb1 1 24 192748+ fd Linux raid autodetect
/dev/sdb2 25 1044 8193150 5 Extended
/dev/sdb5 25 73 393561 fd Linux raid autodetect
/dev/sdb6 74 1044 7799526 fd Linux raid autodetect
shian:~# mdadm --create /dev/md0 --level=1 --raid-disks=2 missing /dev/sdb1
mdadm: array /dev/md0 started.
shian:~# mdadm --create /dev/md1 --level=1 --raid-disks=2 missing /dev/sdb5
mdadm: array /dev/md1 started.
shian:~# mdadm --create /dev/md2 --level=1 --raid-disks=2 missing /dev/sdb6
mdadm: array /dev/md2 started.
shian:~# mkfs.ext2 /dev/md0
shian:~# mkswap /dev/md1
shian:~# mkfs.ext3 /dev/md2
shian:~# cd /etc/mdadm
shian:/etc/mdadm# cp mdadm.conf mdadm.conf.`date +%y%m%d`
shian:/etc/mdadm# echo "DEVICE partitions" > mdadm.conf
shian:/etc/mdadm# mdadm --detail --scan >> mdadm.conf
shian:~# mkdir /mnt/md0
shian:~# mkdir /mnt/md2
shian:~# mount /dev/md0 /mnt/md0
shian:~# mount /dev/md2 /mnt/md2
# /etc/fstab: static file system information.
#
#
proc /proc proc defaults 0 0
/dev/md2 / ext3 defaults,errors=remount-ro 0 1
/dev/md0 /boot ext2 defaults 0 2
/dev/md1 none swap sw 0 0
/dev/hdc /media/cdrom0 udf,iso9660 user,noauto 0 0
/dev/fd0 /media/floppy0 auto rw,user,noauto 0 0
# Línea original
#title Debian GNU/Linux, kernel 2.6.18-4-686
#root (hd0,0)
#kernel /vmlinuz-2.6.18-4-686 root=/dev/sda6 ro
#initrd /initrd.img-2.6.18-4-686
#savedefault
# Nuevas líneas
title Debian GNU/Linux, kernel 2.6.18-4-686 (HD1)
root (hd1,0)
kernel /vmlinuz-2.6.18-4-686 root=/dev/md2 ro
initrd /initrd.img-2.6.18-4-686
savedefault
title Debian GNU/Linux, kernel 2.6.18-4-686 (HD0)
root (hd0,0)
kernel /vmlinuz-2.6.18-4-686 root=/dev/md2 ro
initrd /initrd.img-2.6.18-4-686
savedefault
shian:~# update-initramfs -u
update-initramfs: Generating /boot/initrd.img-2.6.18-4-686
shian:~# cp -ax / /mnt/md2
shian:~# cd /boot/
shian:/boot# cp -ax . /mnt/md0
shian:~# grub
grub> root (hd0,0)
Filesystem type is ext2fs, partition type 0x83
grub> setup (hd0)
Checking if "/boot/grub/stage1" exists... no
Checking if "/grub/stage1" exists... yes
Checking if "/grub/stage2" exists... yes
Checking if "/grub/e2fs_stage1_5" exists... yes
Running "embed /grub/e2fs_stage1_5 (hd0)"... 15 sectors are embedded.
succeeded
Running "install /grub/stage1 (hd0) (hd0)1+15 p (hd0,0)/grub/stage2 /grub/menu.lst"... succeeded
Done.
grub> root (hd1,0)
Filesystem type is ext2fs, partition type 0xfd
grub> setup (hd1)
Checking if "/boot/grub/stage1" exists... no
Checking if "/grub/stage1" exists... yes
Checking if "/grub/stage2" exists... yes
Checking if "/grub/e2fs_stage1_5" exists... yes
Running "embed /grub/e2fs_stage1_5 (hd1)"... 15 sectors are embedded.
succeeded
Running "install /grub/stage1 (hd1) (hd1)1+15 p (hd1,0)/grub/stage2 /grub/menu.lst"... succeeded
Done.
shian:~# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/md2 7.4G 509M 6.5G 8% /
tmpfs 63M 0 63M 0% /lib/init/rw
udev 10M 100K 10M 1% /dev
tmpfs 63M 0 63M 0% /dev/shm
/dev/md0 183M 13M 161M 8% /boot
shian:~# mount
/dev/md2 on / type ext3 (rw,errors=remount-ro)
tmpfs on /lib/init/rw type tmpfs (rw,nosuid,mode=0755)
proc on /proc type proc (rw,noexec,nosuid,nodev)
sysfs on /sys type sysfs (rw,noexec,nosuid,nodev)
udev on /dev type tmpfs (rw,mode=0755)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev)
devpts on /dev/pts type devpts (rw,noexec,nosuid,gid=5,mode=620)
/dev/md0 on /boot type ext2 (rw)
shian:~# fdisk /dev/sda
...
Command (m for help): p
Disk /dev/sda: 8589 MB, 8589934592 bytes
255 heads, 63 sectors/track, 1044 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sda1 1 24 192748+ fd Linux raid autodetect
/dev/sda2 25 1044 8193150 5 Extended
/dev/sda5 25 73 393561 fd Linux raid autodetect
/dev/sda6 74 1044 7799526 fd Linux raid autodetect
...
shian:~# mdadm --add /dev/md0 /dev/sda1
mdadm: added /dev/sda1
shian:~# mdadm --add /dev/md1 /dev/sda5
mdadm: added /dev/sda5
shian:~# mdadm --add /dev/md2 /dev/sda6
mdadm: added /dev/sda6
shian:~# cat /proc/mdstat
Personalities : [raid1] [raid6] [raid5] [raid4]
md2 : active raid1 sda6[2] sdb6[1]
7799424 blocks [2/1] [_U]
[=====>...............] recovery = 25.2% (1967936/7799424) finish=1.1min speed=81997K/sec
md1 : active raid1 sda5[0] sdb5[1]
393472 blocks [2/2] [UU]
md0 : active raid1 sda1[0] sdb1[1]
192640 blocks [2/2] [UU]
unused devices:
Un vez terminada la reconstrucción tendremos listo el sistema. Ahora, si queremos probar que todo funciona correctamente podemos reinicar de nuevo la máquina y comprobar que es capaz de arrancar desde cualquiera de los dos discos.
Con este tipo de configuración estamos seguros de que aunque falle un disco nuestro servidor estará disponible y no tendremos que reinstalar ni reconfigurar nada. Sólo será necesario cambiar el disco defectuoso, reconstruir el raid y reconfigurar el grub.
Suscribirse a:
Entradas (Atom)